
Here's the summary of meek's CDN fees for April 2015.
App Engine + Amazon + Azure = total by month February 2014 $0.09 + -- + -- = $0.09 March 2014 $0.00 + -- + -- = $0.00 April 2014 $0.73 + -- + -- = $0.73 May 2014 $0.69 + -- + -- = $0.69 June 2014 $0.65 + -- + -- = $0.65 July 2014 $0.56 + $0.00 + -- = $0.56 August 2014 $1.56 + $3.10 + -- = $4.66 September 2014 $4.02 + $4.59 + $0.00 = $8.61 October 2014 $40.85 + $130.29 + $0.00 = $171.14 November 2014 $224.67 + $362.60 + $0.00 = $587.27 December 2014 $326.81 + $417.31 + $0.00 = $744.12 January 2015 $464.37 + $669.02 + $0.00 = $1133.39 February 2015 $650.53 + $604.83 + $0.00 = $1255.36 March 2015 $690.29 + $815.68 + $0.00 = $1505.97 April 2015 $886.43 + $785.37 + $0.00 = $1671.80 -- total by CDN $3292.25 + $3792.79 + $0.00 = $7085.04 grand total
https://metrics.torproject.org/userstats-bridge-transport.html?graph=usersta...
The number of simultaneous users increased hugely in April, from 2000 to around 5000. There are big increases around April 9 and April 15, which I conjecture were caused by a performance improvement in meek-azure and its coverage in TWN. meek-azure used to be hugely bottlenecked, but now it should handle as many users as the others. https://lists.torproject.org/pipermail/tor-dev/2015-April/008637.html https://blog.torproject.org/blog/tor-weekly-news-%E2%80%94-april-15th-2015
We moved over 10 TB in April.
Because of meek's extra layer of indirection, it doesn't correctly compute per-country user statistics (the server sees the IP address of the CDN, not of the actual user). Now that a nontrivial fraction of bridge users use meek, a nontrivial fraction of bridge users are being miscounted. Keep that in mind when you look at the per-country bridge user graphs--if users are connecting through meek, they don't count towards that country's total. Here is a ticket that aims to fix the issue by passing the client IP through the CDN. https://trac.torproject.org/projects/tor/ticket/13171
If you want to help reduce costs, you can 1. Use meek-azure; it's still covered through a grant for the next four months. 2. Set up your own App Engine or CDN account. Then you can pay for your own usage (it might even be free depending on how much you use). Here are instructions on how to set up your own: https://gitweb.torproject.org/pluggable-transports/meek.git/tree/appengine/R... https://trac.torproject.org/projects/tor/wiki/doc/meek#AmazonCloudFront https://trac.torproject.org/projects/tor/wiki/doc/meek#MicrosoftAzure Then you will have to enter a bridge line manually. Follow the instructions at https://trac.torproject.org/projects/tor/wiki/doc/meek#Howtochangethefrontdo... but instead of changing the "front=" part, change the "url=" part. For example, bridge meek 0.0.2.0:1 url=https://<myappname>.appspot.com/ front=www.google.com
== App Engine a.k.a. meek-google ==
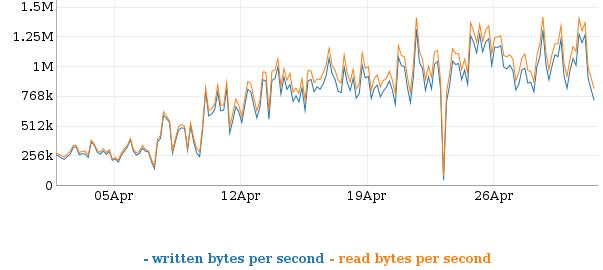
Both bandwidth and instance hours were up about 19%.
Here is how the Google costs broke down: 6304 GB $756.59 2597 instance hours $129.84 Compared to the previous month: 5316 GB $637.93 2173 instance hours $108.64
https://globe.torproject.org/#/bridge/88F745840F47CE0C6A4FE61D827950B06F9E45...
== Amazon a.k.a. meek-amazon ==
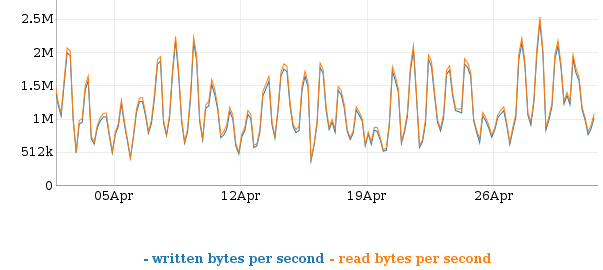
Both usage and cost were down a bit from the previous month.
Asia Pacific (Singapore) 114M requests $136.79 884 GB $117.92 Asia Pacific (Sydney) 443K requests $0.55 3 GB $0.34 Asia Pacific (Tokyo) 51M requests $61.03 305 GB $39.32 EU (Ireland) 173M requests $208.17 1598 GB $127.21 South America (Sao Paulo) 5M requests $9.91 23 GB $5.31 US East (Northern Virginia) 46M requests $45.56 418 GB $33.26 -- total 389M requests $462.01 3231 GB $323.36
https://globe.torproject.org/#/bridge/3FD131B74D9A96190B1EE5D31E91757FADA1A4...
== Azure a.k.a. meek-azure ==
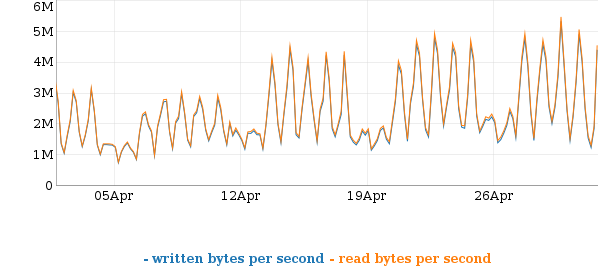
meek-azure increased a lot because of improved performance this month.
https://onionoo.torproject.org/bandwidth?fingerprint=AA033EEB61601B2B7312D89... Estimated bandwidth use this month: 2015-04 1982 GB Compared to last month: 2015-03 737 GB
https://globe.torproject.org/#/bridge/AA033EEB61601B2B7312D89B62AAA23DC3ED8A...
David Fifield
Earlier reports in this series: https://lists.torproject.org/pipermail/tor-dev/2014-August/007429.html https://lists.torproject.org/pipermail/tor-dev/2014-October/007576.html https://lists.torproject.org/pipermail/tor-dev/2014-November/007716.html https://lists.torproject.org/pipermail/tor-dev/2014-December/007916.html https://lists.torproject.org/pipermail/tor-dev/2015-January/008082.html https://lists.torproject.org/pipermail/tor-dev/2015-February/008235.html https://lists.torproject.org/pipermail/tor-dev/2015-March/008427.html https://lists.torproject.org/pipermail/tor-dev/2015-April/008596.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}

David Fifield:
Here's the summary of meek's CDN fees for April 2015.
total by CDN $3292.25 + $3792.79 + $0.00 = $7085.04 grand total https://metrics.torproject.org/userstats-bridge-transport.html?graph=usersta...
Yikes! Are these costs covered by a grant or anything? Should we be running a donations campaign?
If you want to help reduce costs, you can
- Use meek-azure; it's still covered through a grant for the next four months.
- Set up your own App Engine or CDN account. Then you can pay for your own usage (it might even be free depending on how much you use). Here are instructions on how to set up your own: https://gitweb.torproject.org/pluggable-transports/meek.git/tree/appengine/R... https://trac.torproject.org/projects/tor/wiki/doc/meek#AmazonCloudFront https://trac.torproject.org/projects/tor/wiki/doc/meek#MicrosoftAzure Then you will have to enter a bridge line manually. Follow the instructions at https://trac.torproject.org/projects/tor/wiki/doc/meek#Howtochangethefrontdo... but instead of changing the "front=" part, change the "url=" part. For example, bridge meek 0.0.2.0:1 url=https://<myappname>.appspot.com/ front=www.google.com
Please let me know if anyone takes you up on this!
I am happy to add the meek bridges of anyone who does this as an option in Tor Browser. We can add logic to round robin or randomly select between the set of meek providers for a given meek type upon first install, or even for every browser startup.
Given your costs, it also seems worthwhile for us to fund development to improve this situation, so that meek remains a transport of last resort rather than people's first choice.
Here's a couple options:
1. We can add a browser notification box for meek users that either tells them about meek-azure, or tells them that now that Tor Browser works, they can use it to visit https://bridges.torproject.org to get a bridge type that doesn't cost so much money.
2. Perhaps cleaner: if BridgeDB itself were accessible through a domain front, we could export its captcha and bridge distribution through an API on this domain front. Once your IP forwarding in https://trac.torproject.org/projects/tor/ticket/13171 is solved, BridgeDB even could still make use of its IP-based hashring logic.
If we make use of this API in Tor Launcher (and we will, as soon as it exists — I'd even pull a crazy and roll it out in the middle of a stable, given the rapid rate of increase in these costs), users would not need to know the magic incantations to access this front, and new bridges could be obtained behind the scenes for them. All they would have to do is keep solving captchas until something worked (until we also implement some kind of fancy crypto like RBridge).
Now that we have a browser updater, I think it is also OK for us to provide autoprobing options for Tor Launcher, so long as the user is informed what this means before they select it, and it only happens once.
The autoprobing could then keep asking for non-meek bridges for either a given type of the user's choice, or optionally all non-meek types (with an additional warning that this increases their risk of being discovered as a Tor user).
Would you and/or Isis be able to work on this on the backend? If not, can either of you recommend someone that might be able to help with the domain fronting bits and other bits involved?

On Tue, May 5, 2015 at 9:22 PM, Mike Perry mikeperry@torproject.org wrote:
Yikes!
Given your costs, it also seems worthwhile for us to fund development to improve this situation, so that meek remains a transport of last resort rather than people's first choice.
Here's a couple options:
- We can add a browser notification box for meek users that either
Upon meek's first reports I wondered about costs and if users were just picking it on whim. I'd suggest Tor present some sort of ordered choice list that needs affirmative education and interactive ack to use. Increasing on cost or capability to encourage use of least common denominator. Possibly even an automated test. 1) plain client 2) obfs / bridge 3) meek I don't follow these tech so such list could already exist.

Mike Perry wrote:
David Fifield:
Here's the summary of meek's CDN fees for April 2015.
total by CDN $3292.25 + $3792.79 + $0.00 = $7085.04 grand total https://metrics.torproject.org/userstats-bridge-transport.html?graph=usersta...
Yikes! Are these costs covered by a grant or anything? Should we be running a donations campaign?
If you want to help reduce costs, you can
- Use meek-azure; it's still covered through a grant for the next
four months. 2. Set up your own App Engine or CDN account. Then you can pay for your own usage (it might even be free depending on how much you use). Here are instructions on how to set up your own:
https://gitweb.torproject.org/pluggable-transports/meek.git/tree/appengine/R...
https://trac.torproject.org/projects/tor/wiki/doc/meek#AmazonCloudFront
https://trac.torproject.org/projects/tor/wiki/doc/meek#MicrosoftAzure Then you will have to enter a bridge line manually. Follow the instructions at
https://trac.torproject.org/projects/tor/wiki/doc/meek#Howtochangethefrontdo... but instead of changing the "front=" part, change the "url=" part. For example, bridge meek 0.0.2.0:1 url=https://<myappname>.appspot.com/ front=www.google.com
Please let me know if anyone takes you up on this!
I am happy to add the meek bridges of anyone who does this as an option in Tor Browser. We can add logic to round robin or randomly select between the set of meek providers for a given meek type upon first install, or even for every browser startup.
If there were some randomization logic included, I'd be happy to contribute an App Engine or Amazon meek access point. If a few people did that, the costs might be more manageable. But also the stats might be a bit harder to aggregate (which might be important if David is writing a thesis/paper/etc).
Either way, way to go =)
best, Griffin
On Tue, May 05, 2015 at 11:04:58PM -0400, Griffin Boyce wrote:
Mike Perry wrote:
David Fifield:
Here's the summary of meek's CDN fees for April 2015.
total by CDN $3292.25 + $3792.79 + $0.00 = $7085.04 grand total https://metrics.torproject.org/userstats-bridge-transport.html?graph=usersta...
Yikes! Are these costs covered by a grant or anything? Should we be running a donations campaign?
If you want to help reduce costs, you can
- Use meek-azure; it's still covered through a grant for the next four months.
- Set up your own App Engine or CDN account. Then you can pay for your own usage (it might even be free depending on how much you use). Here are instructions on how to set up your own:
https://gitweb.torproject.org/pluggable-transports/meek.git/tree/appengine/R... https://trac.torproject.org/projects/tor/wiki/doc/meek#AmazonCloudFront https://trac.torproject.org/projects/tor/wiki/doc/meek#MicrosoftAzure Then you will have to enter a bridge line manually. Follow the instructions at https://trac.torproject.org/projects/tor/wiki/doc/meek#Howtochangethefrontdo... but instead of changing the "front=" part, change the "url=" part. For example, bridge meek 0.0.2.0:1 url=https://<myappname>.appspot.com/ front=www.google.com
Please let me know if anyone takes you up on this!
I am happy to add the meek bridges of anyone who does this as an option in Tor Browser. We can add logic to round robin or randomly select between the set of meek providers for a given meek type upon first install, or even for every browser startup.
If there were some randomization logic included, I'd be happy to contribute an App Engine or Amazon meek access point. If a few people did that, the costs might be more manageable. But also the stats might be a bit harder to aggregate (which might be important if David is writing a thesis/paper/etc).
Thanks Griffin. At this point we'd need, what, 60 operators in order to cost on average $30/month? At current usage rates.
I think we already have plenty of aggregated stats. It's been nice to be able to separate cleanly amazon/azure/google, but we shouldn't try to keep that forever at the expense of becoming more scalable.

Mike Perry transcribed 5.1K bytes:
[…]
- Perhaps cleaner: if BridgeDB itself were accessible through a domain
front, we could export its captcha and bridge distribution through an API on this domain front. Once your IP forwarding in https://trac.torproject.org/projects/tor/ticket/13171 is solved, BridgeDB even could still make use of its IP-based hashring logic.
Maybe don't set the HTTP header name for the forwarded client IP to "X-Forwarded-For". Otherwise, it will probably get overridden by the Apache server which acts as a reverse proxy in front of BridgeDB's Twisted servers. Just set it to something else, e.g. "X-Domain-Fronted-For".
Then, on the BridgeDB side, it's easy: I'd need to add logic to BridgeDB to handle preferring "X-Domain-Fronted-For", "X-Forwarded-For", then request IP, in that order.
If we make use of this API in Tor Launcher (and we will, as soon as it exists — I'd even pull a crazy and roll it out in the middle of a stable, given the rapid rate of increase in these costs), users would not need to know the magic incantations to access this front, and new bridges could be obtained behind the scenes for them. All they would have to do is keep solving captchas until something worked (until we also implement some kind of fancy crypto like RBridge).
Perhaps the "BridgeDB API" part of what you want is the Tor Browser bridge distributor that I mentioned in §3.1, SOW.9., in my Statement of Work [0] for OTF?
Additionally, SOW.9. is actually the chronological precursor to SOW.10., the latter of which is implementing rBridge (or at least getting started on it). (Work on this is still waiting on OTF to officially grant me the fellowship, along with the other prerequisite tasks getting finished.)
But just to be clear — since it sounds like you've asked for several new things in that last paragraph :) — which do you want:
1. Tor Browser users use meek to get to BridgeDB, to get non-meek bridges by: 1.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 1.b. Solving a CAPTCHA on a BridgeDB web page.
2. Tor Browser users use BridgeDB's domain front, to get non-meek bridges by: 2.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 2.b. Solving a CAPTCHA on a BridgeDB web page.
If you want #2, then we're essentially transferring the domain-fronting costs (and the DDoS risks) from meek to BridgeDB, and we'd need to decide who is going to maintain that service, and who is going to pay for it. Could The Tor Project fund BridgeDB domain fronting?
As far as maintenance goes, the threat to any of our domain fronts, including meek and any BridgeDB domain fronts, from China's Great Cannon waging economic counter-counter-warfare by attacking us (like they did to GreatFire.org) is something which must be taken into account. Will the maintainer of this service need to wake up to emergency, the-request-rate-is-skyrocketing, emails at 4AM to shut the service down? Or do we already have technical measures to detect DDoS and prevent $30,000+/day CDN bills? Further, what happens when #2 is being DDoS-ed? Should we fallback to #1? Should we have both, and some strategy for balancing between the two?
Now that we have a browser updater, I think it is also OK for us to provide autoprobing options for Tor Launcher, so long as the user is informed what this means before they select it, and it only happens once.
Probing all of the different Pluggable Transport types simultaneously provides an excellent training classifier for DPI boxes to learn what new Pluggable Transport traffic looks like.
As long as it happens only once, and only uses the bridges bundled in Tor Browser, I don't see any issue with auto-selecting from the drop-down of transport methodnames in a predefined order. It's what users do anyway.
The autoprobing could then keep asking for non-meek bridges for either a given type of the user's choice, or optionally all non-meek types (with an additional warning that this increases their risk of being discovered as a Tor user).
If the autoprobing is going to include asking BridgeDB (multiple times?) for different types of bridges in the process, whether through a BridgeDB domain front or not, then I think there needs to be more discussion…
* Do you think could you explain more about the steps this autoprobing entails?
* Is the autoprobing meant to solve the issue of not knowing which transport will work? Or the problem of not knowing whether the bridges in Tor Browser are already blocked? Or some other problem?
* Does BridgeDB continue to always normally answer with one transport methodname at a time, unless the "russianroulette" meta-transport type is requested?
If we follow BridgeDB's spec, [1] and we allow wish for the logic controlling how Tor Browser users are handled to be separate (and thus more maintainable), then this will require a new bridge Distributor, and we should probably start thinking about the threat model/security requirements, and behaviours, of the new Distributor. Some design questions we'll need to answer include:
* Should all points on the Distributor's hashring be reachable at a given time (i.e., should there be some feasible way, at any given point in time, to receive any and every Bridge allocated to the Distributor)?
* Or should the Distributor's hashring rotate per time period? Or should it have sub-hashrings which rotate in and out of commission?
* Should it attempt to balance the distribution of clients to Bridges, so that a (few) Bridge(s) at a time aren't hit with tons of new clients?
* Should it treat users coming from the domain front as separate from those coming from elsewhere? (Is is even possible for clients to come from elsewhere? Can clients use Tor to reach this distributor? Can Tor Browser connect directly to BridgeDB, not through the domain front?)
* If we're going to do autoprobing, should it still give out a maximum of three Bridges per request? More? Less?
Would you and/or Isis be able to work on this on the backend? If not, can either of you recommend someone that might be able to help with the domain fronting bits and other bits involved?
I'm in. Yawning mentioned wanting to work on this too. :)
[0]: https://people.torproject.org/~isis/otf-etfp-sow.pdf#subsection.3.1 [1]: https://gitweb.torproject.org/torspec.git/tree/bridgedb-spec.txt
isis:
Mike Perry transcribed 5.1K bytes:
[…]
- Perhaps cleaner: if BridgeDB itself were accessible through a domain
front, we could export its captcha and bridge distribution through an API on this domain front. Once your IP forwarding in https://trac.torproject.org/projects/tor/ticket/13171 is solved, BridgeDB even could still make use of its IP-based hashring logic.
Maybe don't set the HTTP header name for the forwarded client IP to "X-Forwarded-For". Otherwise, it will probably get overridden by the Apache server which acts as a reverse proxy in front of BridgeDB's Twisted servers. Just set it to something else, e.g. "X-Domain-Fronted-For".
Then, on the BridgeDB side, it's easy: I'd need to add logic to BridgeDB to handle preferring "X-Domain-Fronted-For", "X-Forwarded-For", then request IP, in that order.
If we make use of this API in Tor Launcher (and we will, as soon as it exists — I'd even pull a crazy and roll it out in the middle of a stable, given the rapid rate of increase in these costs), users would not need to know the magic incantations to access this front, and new bridges could be obtained behind the scenes for them. All they would have to do is keep solving captchas until something worked (until we also implement some kind of fancy crypto like RBridge).
Perhaps the "BridgeDB API" part of what you want is the Tor Browser bridge distributor that I mentioned in §3.1, SOW.9., in my Statement of Work [0] for OTF?
Yes, this is exactly what I want. With respect to SOW.9.1, consider it feasible! Mission Accomplished! ;)
Additionally, SOW.9. is actually the chronological precursor to SOW.10., the latter of which is implementing rBridge (or at least getting started on it). (Work on this is still waiting on OTF to officially grant me the fellowship, along with the other prerequisite tasks getting finished.)
But just to be clear — since it sounds like you've asked for several new things in that last paragraph :) — which do you want:
Tor Browser users use meek to get to BridgeDB, to get non-meek bridges by: 1.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 1.b. Solving a CAPTCHA on a BridgeDB web page.
Tor Browser users use BridgeDB's domain front, to get non-meek bridges by: 2.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 2.b. Solving a CAPTCHA on a BridgeDB web page.
If you want #2, then we're essentially transferring the domain-fronting costs (and the DDoS risks) from meek to BridgeDB, and we'd need to decide who is going to maintain that service, and who is going to pay for it. Could The Tor Project fund BridgeDB domain fronting?
I proposed two things in my original email. My #1 is your #1.b. My #2 is your #2.a.
For my #2 (your #2.a), what I want is a separate domain front for BridgeDB. It makes the most sense to me for Tor to run its own domain front for this.
If for some reason #2.a can't be done, we could do #1.a and use all of meek+Tor, but this seems excessive, slow, and potentially confusing for users (their Tor client would have to bootstrap twice for each bridge set they test).
I only consider my #1 and #1.b emergency stopgaps, though. In fact, if any aspect of this this process is too slow and/or confusing, we won't take any load off of meek (unless the browser also starts regularly yelling at meek users to donate or something).
As far as maintenance goes, the threat to any of our domain fronts, including meek and any BridgeDB domain fronts, from China's Great Cannon waging economic counter-counter-warfare by attacking us (like they did to GreatFire.org) is something which must be taken into account. Will the maintainer of this service need to wake up to emergency, the-request-rate-is-skyrocketing, emails at 4AM to shut the service down?
I would love to hear how David deals with this risk since the Great Cannon incident.
Honestly, though, I think this is less likely now. If China wasn't somehow discouraged from this behavior via some diplomatic backchannel or just general public backlash, GreatFire.org would probably still be under attack right now.
Either way, it does seem wise to structure this such that multiple people can respond to emergencies here, and that individuals like you and/or David aren't on the hook for the financial damages.
Or do we already have technical measures to detect DDoS and prevent $30,000+/day CDN bills? Further, what happens when #2 is being DDoS-ed? Should we fallback to #1? Should we have both, and some strategy for balancing between the two?
I think trying to fall back or balance between the two is unlikely to save us much, and will just introduce excessive implementation complexity.
If they're going to attack domain fronting usage of Tor, it seems to me that they will attack both meek and BridgeDB.
Now that we have a browser updater, I think it is also OK for us to provide autoprobing options for Tor Launcher, so long as the user is informed what this means before they select it, and it only happens once.
Probing all of the different Pluggable Transport types simultaneously provides an excellent training classifier for DPI boxes to learn what new Pluggable Transport traffic looks like.
As long as it happens only once, and only uses the bridges bundled in Tor Browser, I don't see any issue with auto-selecting from the drop-down of transport methodnames in a predefined order. It's what users do anyway.
Oh, yes. I am still against "connect to all of the things at the same time." The probing I had in mind was to cycle through the transport list and try each type, except also obtain the bridges for each type from BridgeDB.
I also think we should be careful about the probing order. I want to probe the most popular and resilient transports (such as obfs4) first.
The autoprobing could then keep asking for non-meek bridges for either a given type of the user's choice, or optionally all non-meek types (with an additional warning that this increases their risk of being discovered as a Tor user).
If the autoprobing is going to include asking BridgeDB (multiple times?) for different types of bridges in the process, whether through a BridgeDB domain front or not, then I think there needs to be more discussion…
- Do you think could you explain more about the steps this autoprobing entails?
1. User starts a fresh Tor Browser (or one that fails to bootstrap) 2. User clicks "Configure" instead of "Connect" 3. User says they are censored 4. User selects a third radio button on the bridge dialog "Please help me obtain bridges". 5. Tor Browser launches a JSON-RPC request to BridgeDB's domain front for bridges of type $TYPE 6. BridgeDB responds with a Captcha 7. User solves captcha; response is posted back to BridgeDB. 8. BridgeDB response with bridges (or a captcha error) 9. Tor Launcher attempts to bootstrap with these bridges. 10. If bootstrap fails, goto step 5.
The number of loops for steps 5-10 for each $TYPE probably require some intuition on how frequently we expect bridges that we hand out to be blocked due to scraping, and how many bridge addresses we really want to hand out per Captcha+IP address combination.
Later, we can replace Captchas with future RBridge-style crypto, though we should design the domain front independently from RBridge, IMO.
- Is the autoprobing meant to solve the issue of not knowing which transport will work? Or the problem of not knowing whether the bridges in Tor Browser are already blocked? Or some other problem?
Both problems at once, though I suspect (or at least hope) that the current transport types included with Tor Browser are more likely to be blocked by scraping BridgeDB for IP addresses than by DPI.
If we're shipping transports known to be blocked by DPI, we should be phasing them out of Tor Browser, and definitely not using them for this autoprobing business.
- Does BridgeDB continue to always normally answer with one transport methodname at a time, unless the "russianroulette" meta-transport type is requested?
Yes, only one transport should be tested at a time, to avoid the possibility of bad transports revealing the IP addresses of the good ones by testing them in combination.
If we follow BridgeDB's spec, [1] and we allow wish for the logic controlling how Tor Browser users are handled to be separate (and thus more maintainable), then this will require a new bridge Distributor, and we should probably start thinking about the threat model/security requirements, and behaviours, of the new Distributor. Some design questions we'll need to answer include:
Should all points on the Distributor's hashring be reachable at a given time (i.e., should there be some feasible way, at any given point in time, to receive any and every Bridge allocated to the Distributor)?
Or should the Distributor's hashring rotate per time period? Or should it have sub-hashrings which rotate in and out of commission?
Should it attempt to balance the distribution of clients to Bridges, so that a (few) Bridge(s) at a time aren't hit with tons of new clients?
Should it treat users coming from the domain front as separate from those coming from elsewhere? (Is is even possible for clients to come from elsewhere? Can clients use Tor to reach this distributor? Can Tor Browser connect directly to BridgeDB, not through the domain front?)
If we're going to do autoprobing, should it still give out a maximum of three Bridges per request? More? Less?
Personally, I think the domain fronting distributor should behave identically to the closest equivalent distributor that isn't domain fronted, both to reduce implementation complexity, and to keep the system easy to reason about.
Before RBridge is implemented, this would mean using the X-Domain-Fronted-For header's IP address as if it were the real IP address, and index into the hashrings in the same way as we do with the web distributor.
I could see an argument that the set of bridges held by the domain fronting distributor should be kept separate from the web distributor, because heck, way more people should be able to access the domain fronted version, and maybe we want to drastically reduce the web distributor's pool because nobody can reach it (except for whitelisted scrapers and people who don't really need bridges).
However, if you do keep the domain front pool separate from the web distributor pool, you should ensure that you also properly handle the case where Tor IP addresses appear in the X-Domain-Fronted-For header. Again, for this case, I think the simplest answer is "use the same rules as the current web distributor does", though if the domain front pool is separate, perhaps the Tor fraction should be much smaller.
Would you and/or Isis be able to work on this on the backend? If not, can either of you recommend someone that might be able to help with the domain fronting bits and other bits involved?
I'm in. Yawning mentioned wanting to work on this too. :)
Great!
WARNING: much text. so email. very long.
Mike Perry transcribed 13K bytes:
isis:
Additionally, SOW.9. is actually the chronological precursor to SOW.10., the latter of which is implementing rBridge (or at least getting started on it). (Work on this is still waiting on OTF to officially grant me the fellowship, along with the other prerequisite tasks getting finished.)
But just to be clear — since it sounds like you've asked for several new things in that last paragraph :) — which do you want:
Tor Browser users use meek to get to BridgeDB, to get non-meek bridges by: 1.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 1.b. Solving a CAPTCHA on a BridgeDB web page.
Tor Browser users use BridgeDB's domain front, to get non-meek bridges by: 2.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 2.b. Solving a CAPTCHA on a BridgeDB web page.
If you want #2, then we're essentially transferring the domain-fronting costs (and the DDoS risks) from meek to BridgeDB, and we'd need to decide who is going to maintain that service, and who is going to pay for it. Could The Tor Project fund BridgeDB domain fronting?
I proposed two things in my original email. My #1 is your #1.b. My #2 is your #2.a.
For my #2 (your #2.a), what I want is a separate domain front for BridgeDB. It makes the most sense to me for Tor to run its own domain front for this.
Got it.
If for some reason #2.a can't be done, we could do #1.a and use all of meek+Tor, but this seems excessive, slow, and potentially confusing for users (their Tor client would have to bootstrap twice for each bridge set they test).
Well… the cost of the second bootstrap *could* be cut down by persisting the state file from the first bootstrap… but I see what you mean. The user experience doesn't seem like it'd be as smooth.
I only consider my #1 and #1.b emergency stopgaps, though. In fact, if any aspect of this this process is too slow and/or confusing, we won't take any load off of meek (unless the browser also starts regularly yelling at meek users to donate or something).
Agreed, except for the part about yelling at users to donate. Asking nicely and suggesting once or twice, I could get behind. :)
Honestly, though, I think this is less likely now. If China wasn't somehow discouraged from this behavior via some diplomatic backchannel or just general public backlash, GreatFire.org would probably still be under attack right now.
It seems more likely that China was firing the Great Cannon at GreatFire.org as a demonstration/warning.
Now that we have a browser updater, I think it is also OK for us to provide autoprobing options for Tor Launcher, so long as the user is informed what this means before they select it, and it only happens once.
Probing all of the different Pluggable Transport types simultaneously provides an excellent training classifier for DPI boxes to learn what new Pluggable Transport traffic looks like.
As long as it happens only once, and only uses the bridges bundled in Tor Browser, I don't see any issue with auto-selecting from the drop-down of transport methodnames in a predefined order. It's what users do anyway.
Oh, yes. I am still against "connect to all of the things at the same time." The probing I had in mind was to cycle through the transport list and try each type, except also obtain the bridges for each type from BridgeDB.
But why does Tor Browser need to get bridges from BridgeDB, if it doesn't know yet which ones will work? Why not autoprobe with the bundled bridges, then ask BridgeDB for some more of the kind that works?
I also think we should be careful about the probing order. I want to probe the most popular and resilient transports (such as obfs4) first.
Currently, obfs4 isn't blocked anywhere… so why probe at all when we know definitely that the first thing we try is going to work?
The autoprobing could then keep asking for non-meek bridges for either a given type of the user's choice, or optionally all non-meek types (with an additional warning that this increases their risk of being discovered as a Tor user).
If the autoprobing is going to include asking BridgeDB (multiple times?) for different types of bridges in the process, whether through a BridgeDB domain front or not, then I think there needs to be more discussion…
- Do you think could you explain more about the steps this autoprobing entails?
- User starts a fresh Tor Browser (or one that fails to bootstrap)
- User clicks "Configure" instead of "Connect"
- User says they are censored
- User selects a third radio button on the bridge dialog "Please help me obtain bridges".
- Tor Browser launches a JSON-RPC request to BridgeDB's domain front for bridges of type $TYPE
- BridgeDB responds with a Captcha
- User solves captcha; response is posted back to BridgeDB.
- BridgeDB response with bridges (or a captcha error)
- Tor Launcher attempts to bootstrap with these bridges.
- If bootstrap fails, goto step 5.
The number of loops for steps 5-10 for each $TYPE probably require some intuition on how frequently we expect bridges that we hand out to be blocked due to scraping, and how many bridge addresses we really want to hand out per Captcha+IP address combination.
Currently, you get the same bridges every time you ask (for some arbitrary period). This would definitely require a new Distributor on the backend (not a problem, and not difficult, just saying).
Why ask multiple times? Why not just get three bridges per request, and if that appears to be failing to get 99% of users connected to a bridge, increase it to four?
Later, we can replace Captchas with future RBridge-style crypto, though we should design the domain front independently from RBridge, IMO.
Agreed; I'm not proposing any crazy crypto here. Rather, I'd like to know how this Tor Browser Distributor should behave, and preferably also something resembling a rationale for why it behaves that way.
Perhaps also it would be better to make yet another new rBridge Distributor later, separate from the Tor Browser Distributor (this thing needs a name!). I could imagine some old computers running Tails, and some Magickal-Anonymity-Routers-Which-Are-Neither-Secure-Nor-Anonymous might not be capable of running the (modified) rBridge crypto code.
- Is the autoprobing meant to solve the issue of not knowing which transport will work? Or the problem of not knowing whether the bridges in Tor Browser are already blocked? Or some other problem?
Both problems at once, though I suspect (or at least hope) that the current transport types included with Tor Browser are more likely to be blocked by scraping BridgeDB for IP addresses than by DPI.
IMO, the most efficient way is to run a middle relay without the Guard flag, and log every connection from something that isn't currently in the consensus.
FWIW, the number of suspicious attempts to the HTTPS Distributor has dropped substantially in the last four months, and to the email distributor has stayed the about the same. Off the top of my head, this is likely, hopefully, something to do with:
1. actually distributing separate bridges to Tor/proxy users, and actually rate limiting them (!!), [0] [1]
2. actually rotating available bridges, such that large amounts of both time and IP space are required to effectively scrape, [2] [3]
3. semi-automatedly blacklisting stupid email bots, [4]
4. moving away from ReCAPTCHA to our own CAPTCHA module and expiring stale CAPTCHAs after 10 minutes. [5]
If we follow BridgeDB's spec, [1] and we allow wish for the logic controlling how Tor Browser users are handled to be separate (and thus more maintainable), then this will require a new bridge Distributor, and we should probably start thinking about the threat model/security requirements, and behaviours, of the new Distributor. Some design questions we'll need to answer include:
Should all points on the Distributor's hashring be reachable at a given time (i.e., should there be some feasible way, at any given point in time, to receive any and every Bridge allocated to the Distributor)?
Or should the Distributor's hashring rotate per time period? Or should it have sub-hashrings which rotate in and out of commission?
Should it attempt to balance the distribution of clients to Bridges, so that a (few) Bridge(s) at a time aren't hit with tons of new clients?
Should it treat users coming from the domain front as separate from those coming from elsewhere? (Is is even possible for clients to come from elsewhere? Can clients use Tor to reach this distributor? Can Tor Browser connect directly to BridgeDB, not through the domain front?)
If we're going to do autoprobing, should it still give out a maximum of three Bridges per request? More? Less?
Personally, I think the domain fronting distributor should behave identically to the closest equivalent distributor that isn't domain fronted, both to reduce implementation complexity, and to keep the system easy to reason about.
Before RBridge is implemented, this would mean using the X-Domain-Fronted-For header's IP address as if it were the real IP address, and index into the hashrings in the same way as we do with the web distributor.
"Index into the hashrings" is a culmination of rather complicated structures to produce a behaviour particular to the current best known configuration of a particular Distributor.
If you would like it to behave the same as the HTTPS Distributor, should bridges for Tor/proxy users still be kept in a separate subhashring? And users grouped by /32 if IPv6, and /16 if IPv4? And only allow one set of bridges every three hours for non-Tor/proxy users, and four sets for all Tor/proxy users? And rotate sub-sub-hashrings once per day? And expire CAPTCHAs after 10 minutes? And will you accept that, should I need to change any of those things for the HTTPS Distributor, that your Tor Browser Distributor might break?
(I'm goint to start calling the Tor Browser Distributor "Charon", unless someone has less gruesome name.)
Otherwise, it should likely be separate. What problem would be solved by keeping them as the same Distributor, other than (at least at the initial implementation time) the Distributor code won't be duplicated? Also, it's not very much duplication:
(bdb)∃!isisⒶwintermute:(fix/12505-refactor-hashrings_r7 *$<>)~/code/torproject/bridgedb ∴ cloc --quiet lib/bridgedb/https/distributor.py
http://cloc.sourceforge.net v 1.60 T=0.01 s (74.0 files/s, 28780.8 lines/s) ------------------------------------------------------------------------------- Language files blank comment code ------------------------------------------------------------------------------- Python 1 56 183 150 -------------------------------------------------------------------------------
Also, I'm about to finish #12506, giving BridgeDB multi-process support and a speed increase for every Distributor that runs separately.
I could see an argument that the set of bridges held by the domain fronting distributor should be kept separate from the web distributor, because heck, way more people should be able to access the domain fronted version, and maybe we want to drastically reduce the web distributor's pool because nobody can reach it (except for whitelisted scrapers and people who don't really need bridges).
Actually! Current statistical estimates say that many people (~75,000 times per day) can not only reach it, but can get bridges from it. [6] :)
If you want more bridges allocated to the Tor Browser Distributor from the beginning, there's a trick to dump the unallocated bridges into your Distributor as soon as it first exists. That's 1/5th the size of the HTTPS pool, and 2/5ths the size of the email pool; roughly 1,000 bridges.
However, if you do keep the domain front pool separate from the web distributor pool, you should ensure that you also properly handle the case where Tor IP addresses appear in the X-Domain-Fronted-For header. Again, for this case, I think the simplest answer is "use the same rules as the current web distributor does", though if the domain front pool is separate, perhaps the Tor fraction should be much smaller.
Sure.
Fortunately, there are separate structures for handling the current Tor exit list, in memory, in the main process, [7] [8] because I prefer keeping various functionalities organised separately, from generalised to specialised, to reduce code duplication, and increase reusability and maintainability.
No changes required to take Tor users into consideration, or not take them into consideration. ItJustWorks™. :)
[0]: https://bugs.torproject.org/4771#comment:14 [1]: https://bugs.torproject.org/4405 [2]: https://bugs.torproject.org/1839 [3]: https://bugs.torproject.org/15517 [4]: https://bugs.torproject.org/9385 [5]: https://bugs.torproject.org/11215 [6]: https://people.torproject.org/~isis/otf-etfp-sow.pdf#subsection.1.1 [7]: https://gitweb.torproject.org/bridgedb.git/tree/lib/bridgedb/proxy.py [8]: https://gitweb.torproject.org/bridgedb.git/tree/scripts/get-tor-exits
isis:
WARNING: much text. so email. very long.
Right. If I cut your previous text, assume I'm in agreement, not ignoring it.
Mike Perry transcribed 13K bytes:
isis:
Now that we have a browser updater, I think it is also OK for us to provide autoprobing options for Tor Launcher, so long as the user is informed what this means before they select it, and it only happens once.
Probing all of the different Pluggable Transport types simultaneously provides an excellent training classifier for DPI boxes to learn what new Pluggable Transport traffic looks like.
As long as it happens only once, and only uses the bridges bundled in Tor Browser, I don't see any issue with auto-selecting from the drop-down of transport methodnames in a predefined order. It's what users do anyway.
Oh, yes. I am still against "connect to all of the things at the same time." The probing I had in mind was to cycle through the transport list and try each type, except also obtain the bridges for each type from BridgeDB.
But why does Tor Browser need to get bridges from BridgeDB, if it doesn't know yet which ones will work? Why not autoprobe with the bundled bridges, then ask BridgeDB for some more of the kind that works?
Sure, the first autoprobe can (and should) test the local bridges before ask for more, but I expect people are using meek because none of those actually work.
We can do better about trying to sneak fresh bridges into the TBB distribution immediately before every release, but I doubt that will help much, since the adversary can scrape them with just a wget from our git repos.
I also think we should be careful about the probing order. I want to probe the most popular and resilient transports (such as obfs4) first.
Currently, obfs4 isn't blocked anywhere… so why probe at all when we know definitely that the first thing we try is going to work?
Mostly because of IP blocking.
The autoprobing could then keep asking for non-meek bridges for either a given type of the user's choice, or optionally all non-meek types (with an additional warning that this increases their risk of being discovered as a Tor user).
If the autoprobing is going to include asking BridgeDB (multiple times?) for different types of bridges in the process, whether through a BridgeDB domain front or not, then I think there needs to be more discussion…
- Do you think could you explain more about the steps this autoprobing entails?
- User starts a fresh Tor Browser (or one that fails to bootstrap)
- User clicks "Configure" instead of "Connect"
- User says they are censored
- User selects a third radio button on the bridge dialog "Please help me obtain bridges".
- Tor Browser launches a JSON-RPC request to BridgeDB's domain front for bridges of type $TYPE
- BridgeDB responds with a Captcha
- User solves captcha; response is posted back to BridgeDB.
- BridgeDB response with bridges (or a captcha error)
- Tor Launcher attempts to bootstrap with these bridges.
- If bootstrap fails, goto step 5.
The number of loops for steps 5-10 for each $TYPE probably require some intuition on how frequently we expect bridges that we hand out to be blocked due to scraping, and how many bridge addresses we really want to hand out per Captcha+IP address combination.
Currently, you get the same bridges every time you ask (for some arbitrary period). This would definitely require a new Distributor on the backend (not a problem, and not difficult, just saying).
Why ask multiple times? Why not just get three bridges per request, and if that appears to be failing to get 99% of users connected to a bridge, increase it to four?
Handing out four at a time might work better than requesting the same type again and again. Then again, simply trying the other transport types might also work.
How hard is it to get analytics on the requests to BridgeDB? If we give you a special request parameter (like "&justfailed=obfs4") that means "Hey, I'm asking you again for this new transport type because the obfs4 bridges you just gave me didn't work", can you count that? Can you break down that count by GeoIP country for the requesting IP?
That metric will be useful for hints if obfs4 is suddenly blocked in some country, or if by some other mechanism the censor has discovered all/most of the IP addresses of the obfs4 bridges.
FWIW, the number of suspicious attempts to the HTTPS Distributor has dropped substantially in the last four months, and to the email distributor has stayed the about the same. Off the top of my head, this is likely, hopefully, something to do with:
actually distributing separate bridges to Tor/proxy users, and actually rate limiting them (!!), [0] [1]
actually rotating available bridges, such that large amounts of both time and IP space are required to effectively scrape, [2] [3]
semi-automatedly blacklisting stupid email bots, [4]
moving away from ReCAPTCHA to our own CAPTCHA module and expiring stale CAPTCHAs after 10 minutes. [5]
Interesting, I think this might be a good argument for "If it ain't broke, don't fix it" wrt how we hand out bridges for the Domain Front distributor.
Personally, I think the domain fronting distributor should behave identically to the closest equivalent distributor that isn't domain fronted, both to reduce implementation complexity, and to keep the system easy to reason about.
Before RBridge is implemented, this would mean using the X-Domain-Fronted-For header's IP address as if it were the real IP address, and index into the hashrings in the same way as we do with the web distributor.
"Index into the hashrings" is a culmination of rather complicated structures to produce a behaviour particular to the current best known configuration of a particular Distributor.
If you would like it to behave the same as the HTTPS Distributor, should bridges for Tor/proxy users still be kept in a separate subhashring? And users grouped by /32 if IPv6, and /16 if IPv4? And only allow one set of bridges every three hours for non-Tor/proxy users, and four sets for all Tor/proxy users? And rotate sub-sub-hashrings once per day? And expire CAPTCHAs after 10 minutes? And will you accept that, should I need to change any of those things for the HTTPS Distributor, that your Tor Browser Distributor might break?
Yes to all. Well, except the last one. I'd hope you could guarantee API compatibility, at least.
As I said, I think starting out with all of this as it is in the HTTPS distributor is fine, so long as we can measure how many users actually don't need to ask for more bridges of a different type, and figure out some way to change that if it is clearly not working.
Otherwise, it should likely be separate. What problem would be solved by keeping them as the same Distributor, other than (at least at the initial implementation time) the Distributor code won't be duplicated?
I have nothing against keeping them separate, and for just the bridge pool assignments that may be wise, since the access mechanisms are slightly different than the non-domain fronted HTTPS distributor. If retaining the ability to change the behavior for just the Tor Browser distributor also means keeping the implementation separate, that can also work.
I only suspect that when this functionality is in Tor Launcher, it will be the primary way that people get bridges, and should thus have the most bridges out of any distributor, until we start inventing other distributor types to replace it.
After all, Tor Launcher is used by Tails, Tor Browser, Tor Birdy, and Tor Messenger. I bet Orbot will make use of the API too. That's basically the entire Tor userbase, right there.
(I'm goint to start calling the Tor Browser Distributor "Charon", unless someone has less gruesome name.)
Yikes. I'm going to pretend this is just an internal secret project codename and keep it off of user-facing UI :)
I could see an argument that the set of bridges held by the domain fronting distributor should be kept separate from the web distributor, because heck, way more people should be able to access the domain fronted version, and maybe we want to drastically reduce the web distributor's pool because nobody can reach it (except for whitelisted scrapers and people who don't really need bridges).
Actually! Current statistical estimates say that many people (~75,000 times per day) can not only reach it, but can get bridges from it. [6] :)
How do we know these weren't bot/scraper requests? Especially since as you say the suspicious request rate has fallen since you fixed several issues related to the web distributor hash rings and rate limiting?
If you want more bridges allocated to the Tor Browser Distributor from the beginning, there's a trick to dump the unallocated bridges into your Distributor as soon as it first exists. That's 1/5th the size of the HTTPS pool, and 2/5ths the size of the email pool; roughly 1,000 bridges.
1/5 of the HTTPS pool is unlikely to serve the entire Tor userbase long term. I really expect this to be the primary way people get bridges, unless it gets blocked or scraped, or we build something else we like better.
On Wed, May 06, 2015 at 04:36:48AM +0000, isis wrote:
But just to be clear — since it sounds like you've asked for several new things in that last paragraph :) — which do you want:
Tor Browser users use meek to get to BridgeDB, to get non-meek bridges by: 1.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 1.b. Solving a CAPTCHA on a BridgeDB web page.
Tor Browser users use BridgeDB's domain front, to get non-meek bridges by: 2.a. Retrieving and solving a CAPTCHA inside Tor Launcher. 2.b. Solving a CAPTCHA on a BridgeDB web page.
If you want #2, then we're essentially transferring the domain-fronting costs (and the DDoS risks) from meek to BridgeDB, and we'd need to decide who is going to maintain that service, and who is going to pay for it. Could The Tor Project fund BridgeDB domain fronting?
You still have the DoS risk, but in normal usage the costs will be way way less because you're only paying for bootstrapping and not for GNU/Linux ISO downloads or whatever it is people do with Tor. Bandwidth costs across all CDNs are between $0.10 and $0.20 per GB. To reach even one GB would take a million 1K bootstraps.
As far as maintenance goes, the threat to any of our domain fronts, including meek and any BridgeDB domain fronts, from China's Great Cannon waging economic counter-counter-warfare by attacking us (like they did to GreatFire.org) is something which must be taken into account. Will the maintainer of this service need to wake up to emergency, the-request-rate-is-skyrocketing, emails at 4AM to shut the service down? Or do we already have technical measures to detect DDoS and prevent $30,000+/day CDN bills? Further, what happens when #2 is being DDoS-ed? Should we fallback to #1? Should we have both, and some strategy for balancing between the two?
App Engine is nice because you can set a daily cost limit, and the service shuts down after that. It's currently set at $45/day (after we bumped into the previous $40/day limit one day last week :/). It's nice because the maximum damage a DoS can cause (besides shutting down the service) is O(1).
Amazon sucks and they don't have any automatic way to shut down a service. I emailed them and they were very clear about that. The best you can do is set up an email alert at different cost threshold (which I have done). But that requires someone with credentials to be awake and online when it happens. This is the main reason I want to drop Amazon. (Apart from the billing concerns, Amazon's CDN, technically, is nice and fast and reliable.)

Amazon sucks and they don't have any automatic way to shut down a service. I emailed them and they were very clear about that. The best you can do is set up an email alert at different cost threshold (which I have done). But that requires someone with credentials to be awake and online when it happens. This is the main reason I want to drop Amazon. (Apart from the billing concerns, Amazon's CDN, technically, is nice and fast and reliable.)
Would it make sense to add some code to your meek server to monitor bandwidth usage and automatically shut off if a limit is reached?
On Wed, May 06, 2015 at 11:56:36AM -0700, Arthur D. Edelstein wrote:
Amazon sucks and they don't have any automatic way to shut down a service. I emailed them and they were very clear about that. The best you can do is set up an email alert at different cost threshold (which I have done). But that requires someone with credentials to be awake and online when it happens. This is the main reason I want to drop Amazon. (Apart from the billing concerns, Amazon's CDN, technically, is nice and fast and reliable.)
Would it make sense to add some code to your meek server to monitor bandwidth usage and automatically shut off if a limit is reached?
I don't think that helps because I think you will still get charged for requests+bandwidth even if the origin server is unresponsive or returns an error. I could be wrong about this. Yawning wrote some such code a while back.
Even if you cut off all abusive use of bandwidth, if the adversary can figure out how to charge you for requests, they cost $1 per million on Amazon.
Maybe you could rig up something that shuts down the instance? Or does Amazon charge you even then?
On Wed, May 6, 2015 at 12:16 PM, David Fifield david@bamsoftware.com wrote:
On Wed, May 06, 2015 at 11:56:36AM -0700, Arthur D. Edelstein wrote:
Amazon sucks and they don't have any automatic way to shut down a service. I emailed them and they were very clear about that. The best you can do is set up an email alert at different cost threshold (which I have done). But that requires someone with credentials to be awake and online when it happens. This is the main reason I want to drop Amazon. (Apart from the billing concerns, Amazon's CDN, technically, is nice and fast and reliable.)
Would it make sense to add some code to your meek server to monitor bandwidth usage and automatically shut off if a limit is reached?
I don't think that helps because I think you will still get charged for requests+bandwidth even if the origin server is unresponsive or returns an error. I could be wrong about this. Yawning wrote some such code a while back.
Even if you cut off all abusive use of bandwidth, if the adversary can figure out how to charge you for requests, they cost $1 per million on Amazon. _______________________________________________ tor-dev mailing list tor-dev@lists.torproject.org https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-dev
On Wed, May 06, 2015 at 12:56:04PM -0700, Arthur D. Edelstein wrote:
Maybe you could rig up something that shuts down the instance? Or does Amazon charge you even then?
That might work. I found some documentation on an API for CloudFront web distributions: https://docs.aws.amazon.com/AmazonCloudFront/latest/APIReference/Actions_Dis... https://docs.aws.amazon.com/AmazonCloudFront/latest/APIReference/PutConfig.h...
It looks like you can PUT an <enabled>true</enabled>.
It would be nice if this were a separate process apart from meek-server that counts requests and bytes and keeps track of estimated costs. It should be able to send a message to another process somewhere that controls the AWS API keys.
On Tue, May 05, 2015 at 06:22:47PM -0700, Mike Perry wrote:
David Fifield:
Here's the summary of meek's CDN fees for April 2015.
total by CDN $3292.25 + $3792.79 + $0.00 = $7085.04 grand total https://metrics.torproject.org/userstats-bridge-transport.html?graph=usersta...
Yikes! Are these costs covered by a grant or anything? Should we be running a donations campaign?
It's partly covered by grants but not fully.
I'd be happy with donations but I don't want to handle any money. We also need to think about long-term sustainability: usage and costs will continue to increase(at least until the world changes), and donations will need to increase too.
Look at the "1 year" bandwidth graph for meek-google. It's pretty close to linear since October 2014, increasing 400 KB/s/month. https://globe.torproject.org/#/bridge/88F745840F47CE0C6A4FE61D827950B06F9E45...
If you want to help reduce costs, you can
- Use meek-azure; it's still covered through a grant for the next four months.
- Set up your own App Engine or CDN account. Then you can pay for your own usage (it might even be free depending on how much you use). Here are instructions on how to set up your own: https://gitweb.torproject.org/pluggable-transports/meek.git/tree/appengine/R... https://trac.torproject.org/projects/tor/wiki/doc/meek#AmazonCloudFront https://trac.torproject.org/projects/tor/wiki/doc/meek#MicrosoftAzure Then you will have to enter a bridge line manually. Follow the instructions at https://trac.torproject.org/projects/tor/wiki/doc/meek#Howtochangethefrontdo... but instead of changing the "front=" part, change the "url=" part. For example, bridge meek 0.0.2.0:1 url=https://<myappname>.appspot.com/ front=www.google.com
Please let me know if anyone takes you up on this!
I am happy to add the meek bridges of anyone who does this as an option in Tor Browser. We can add logic to round robin or randomly select between the set of meek providers for a given meek type upon first install, or even for every browser startup.
Thanks.
In recommending that people run their own reflectors, I actually had a different use case in mind: that they would run one for themself or for their friends, and not announce it publicly. So basically like setting up any other private proxy, except it works in more places.
Given your costs, it also seems worthwhile for us to fund development to improve this situation, so that meek remains a transport of last resort rather than people's first choice.
I don't have the feeling that it's people's first choice. Rather I think we're seeing new users who were not being served by any of the other transports. It's going to be slower than other transports. On the other hand, not needing to find bridges is a big distinction, and once you have something that works there's little incentive to change it.
Here's a couple options:
- We can add a browser notification box for meek users that either
tells them about meek-azure, or tells them that now that Tor Browser works, they can use it to visit https://bridges.torproject.org to get a bridge type that doesn't cost so much money.
I don't want to lean too hard on meek-azure, because its grant runs out in four months and I don't have a plan to keep it going.
I wouldn't want people to feel guilty when they manage to circumvent censorship, especially if nothing else works for them. But yes, we can probably make some UI and backend changes that make the default options less costly.
- Perhaps cleaner: if BridgeDB itself were accessible through a domain
front, we could export its captcha and bridge distribution through an API on this domain front. Once your IP forwarding in https://trac.torproject.org/projects/tor/ticket/13171 is solved, BridgeDB even could still make use of its IP-based hashring logic.
For this purpose you wouldn't even need the full power of BridgeDB. The list of bridges doesn't need to be kept secret for blocking resistance, so you could even just put the list on a web page and domain-front to download it. (It still might make sense to keep the list secret to hinder financial DoS on the operators, but unless there are a ton of operators, they'll still be enumerable and vulnerable.)
I gave a talk about domin fronting at Stanford and that's what the audience suggested: use a centrally paid-for account only to get a bridge on someone else's account, and then use that bridge for all your data transfer. Then the central costs are limited to bootstrapping.
We'll need some added code for robustness, as we can't expect a large number of bridges to individually be as reliable as the handful of curated ones we have now. Like, if someone turned off their account or they reached their daily cost quota.
Would you and/or Isis be able to work on this on the backend? If not, can either of you recommend someone that might be able to help with the domain fronting bits and other bits involved?
Yeah--I don't want to become a bottleneck in terms of people needing to send email to get added to the list, or anything like that though.
-
 Arthur D. Edelstein
Arthur D. Edelstein -
 David Fifield
David Fifield -
 grarpamp
grarpamp -
 Griffin Boyce
Griffin Boyce -
 isis
isis -
 Mike Perry
Mike Perry