
In the past years we observed sudden drops in Tor usage in certain countries. Some of these events may be attributed to countries specifically wanting to block Tor, as it enables their citizens to circumvent their censorship infrastructure. Other events likely result from country-wide Internet outages that are unrelated to Tor.
Two such events happened in January 2011 in Iran [0] and Egypt [1].
The key point is that we can derive from observed Tor usage when something potentially interesting is going on in a country. We should be able to build a system that keeps track of our daily user estimates per country and automatically sends out a warning whenever there are sudden changes.
George Danezis wrote "An anomaly-based censorship-detection system for Tor" [2]. George's detection code [3] uses our daily user estimates [4] as input and gives a list of sudden upturns and downturns per country as output. We integrated the results of his script in the metrics website [5] to demonstrate what events the detector recognizes as possible censorship events.
For example, the detector would have warned in January 2011 about the events in Iran [6] and Egypt [7], shown as red dots for downturns.
However, as one can see, George's script also detects quite a few false positives. Whenever there's a red or blue dot, the script would have issued a warning for a human to check. It would be neat to reduce these false warnings while still catching the really suspicious events.
Want to help us make our censorship-detection system better? Any suggestion to improve George's algorithm or to come up with an alternative approach to detect possible censorship events in our data would be much appreciated! Let us know if we can help you get started.
[0] https://metrics.torproject.org/users.html?graph=direct-users&start=2011-...
[1] https://metrics.torproject.org/users.html?graph=direct-users&start=2011-...
[2] https://metrics.torproject.org/papers/detector-2011-08-11.pdf
[3] https://gitweb.torproject.org/metrics-tasks.git/tree/HEAD:/task-2718
[4] https://metrics.torproject.org/csv/direct-users.csv
[5] https://metrics.torproject.org/users.html#censorship-events
[6] https://metrics.torproject.org/users.html?graph=direct-users&start=2011-...
[7] https://metrics.torproject.org/users.html?graph=direct-users&start=2011-...

Hi Karsten,
On 14 Sep 2011, at 07:17, Karsten Loesing wrote:
However, as one can see, George's script also detects quite a few false positives. Whenever there's a red or blue dot, the script would have issued a warning for a human to check. It would be neat to reduce these false warnings while still catching the really suspicious events.
Want to help us make our censorship-detection system better? Any suggestion to improve George's algorithm or to come up with an alternative approach to detect possible censorship events in our data would be much appreciated! Let us know if we can help you get started.
Well the easiest thing to do would be to change the parameter which decides whether to send an alert out. According to the paper: "We consider that a ratio of connections is typical if it falls within the 99.99 % percentile of the Normal distribution N(m, v) modelling ratios." Maybe 99.995% or 99.999% would be better?
Can we look at the alerts and categorise them into ones which were not censorship events (false positives) and ones which were events that we would like to be alerted about (true positives). Also look for any censorship events which were missed (false negatives). Then for each event, see how much the ratio of connections diverges from that predicted by the model. If the divergence is larger for true positives than it is for false positives, and there are few false negatives, then the model can be left unchanged, but the alert-criteria needs to be lifted. If the divergence for each of the categories are tightly clustered then the model would have to be changed.
But do remember this is a very challenging problem. The vast majority of the time a censorship event has not happened. This means that even if we have an extremely accurate detector, we will still get quite a few false positives (perhaps more than we do true positives). For the reason, see http://en.wikipedia.org/wiki/Base_rate_fallacy. It might be that we will have to filter out the false negatives manually by asking people in country.
Steven.

Apologies for breaking the thread, I didn't have the original message.
From the mentioned paper (which I've only skimmed):
``The deployed model considers a time interval of seven (7) days to model connection rates (i.e. $t_i - t_{i−1} = 7$ days).''
If I understand correctly, this means trends occurring on a week-to-week basis (or larger periods) are considered and higher-frequency trends are undesirable? In that case, perhaps pre-processing the data by filtering would be useful.
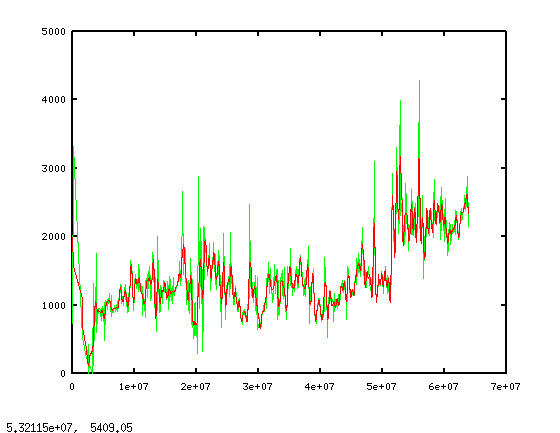
Attached (1.png) is an example (in red) of filtering out all frequencies higher than that corresponding to a one week period, compared to the original data (green). This is the entire data for Switzerland, abscissa in seconds.
The result is a little less noise, which might help with your algorithm.
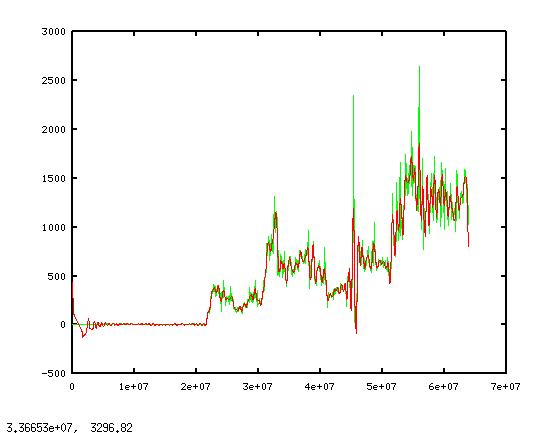
The same filter applied to the Egypt and Iran data (2.png and 3.png respectively) doesn't harm the signal for those two censorship events, at least not by visual inspection. (You'd probably want to use a Hanning window or something, to avoid those artifacts at the extreme ends of the red graphs.)
But filtering like this would also mean that the signal of an event which occurs and is over in less than a week, like this week's, is also lost...
{kind=link}
{kind=link}
{kind=link}
-
 Karsten Loesing
Karsten Loesing -
 Mansour Moufid
Mansour Moufid -
 Steven Murdoch
Steven Murdoch