
Hi all,
I'm looking at some traffic patterns for my Exit relay, and I'm frankly a bit disappointed with the utilization.
Currently it's running at a load average of 0.3-0.5, and CPU idle at 70-80%.
We're not limited on Bandwidth (tests show that our max cap is more than safe to produce), yet, we're barely reaching 20% of our potential allocated traffic.
We've reached "fast" and "guard", and got the "stable" flag as well, so in theory we ought to see traffic move a bit higher than currently.
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
//D.S.

In short, yes.
On Sep 21, 2016 5:02 AM, "D.S. Ljungmark" ljungmark@modio.se wrote:
Hi all,
I'm looking at some traffic patterns for my Exit relay, and I'm frankly a bit disappointed with the utilization.
Currently it's running at a load average of 0.3-0.5, and CPU idle at 70-80%.
We're not limited on Bandwidth (tests show that our max cap is more than safe to produce), yet, we're barely reaching 20% of our potential allocated traffic.
We've reached "fast" and "guard", and got the "stable" flag as well, so in theory we ought to see traffic move a bit higher than currently.
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
//D.S.
-- 8362 CB14 98AD 11EF CEB6 FA81 FCC3 7674 449E 3CFC
tor-relays mailing list tor-relays@lists.torproject.org https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-relays

On 21 Sep 2016, at 20:01, D.S. Ljungmark ljungmark@modio.se wrote:
Hi all,
I'm looking at some traffic patterns for my Exit relay, and I'm frankly a bit disappointed with the utilization.
Currently it's running at a load average of 0.3-0.5, and CPU idle at 70-80%.
We're not limited on Bandwidth (tests show that our max cap is more than safe to produce), yet, we're barely reaching 20% of our potential allocated traffic.
We've reached "fast" and "guard", and got the "stable" flag as well, so in theory we ought to see traffic move a bit higher than currently.
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
How long has the relay been up? What's the fingerprint of your Exit relay? Where is it located?
Have you read: https://blog.torproject.org/blog/lifecycle-of-a-new-relay
Does your processor have AES-NI? Is it reasonably fast? Does Tor have enough sockets available? Does it warn you about any other potential performance issues in its logs?
Have you tried running 2 Tor instances per IPv4 address?
Also, have you tried searching the mailing list archives? This question gets asked and answered at least once a month.
Tim
//D.S.
-- 8362 CB14 98AD 11EF CEB6 FA81 FCC3 7674 449E 3CFC
tor-relays mailing list tor-relays@lists.torproject.org https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-relays
Tim Wilson-Brown (teor)
teor2345 at gmail dot com PGP C855 6CED 5D90 A0C5 29F6 4D43 450C BA7F 968F 094B ricochet:ekmygaiu4rzgsk6n xmpp: teor at torproject dot org

On 21/09/16 15:24, teor wrote:
On 21 Sep 2016, at 20:01, D.S. Ljungmark ljungmark@modio.se wrote:
Hi all,
I'm looking at some traffic patterns for my Exit relay, and I'm frankly a bit disappointed with the utilization.
Currently it's running at a load average of 0.3-0.5, and CPU idle at 70-80%.
We're not limited on Bandwidth (tests show that our max cap is more than safe to produce), yet, we're barely reaching 20% of our potential allocated traffic.
We've reached "fast" and "guard", and got the "stable" flag as well, so in theory we ought to see traffic move a bit higher than currently.
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
How long has the relay been up?
4 years or so. ( current uptime: 11 hours since reboot, it reboots weekly )
The initial rampup time went and scaled up until ~120 Mbit, where it's been stable hovering.
What's the fingerprint of your Exit relay?
5989521A85C94EE101E88B8DB2E68321673F9405
Where is it located?
Sweden, Tele2 AS
Have you read: https://blog.torproject.org/blog/lifecycle-of-a-new-relay
yes
Does your processor have AES-NI? Is it reasonably fast?
Yes, yes. As said, load on the CPU isn't even hitting load 0.4 most of the time, 24% CPU load (user) and 11% (sys) has been the max it's hit over the last week, at the same time it's been hitting 17 MBytes/s in each direction.
Which, frankly, is quite a bit lower than I expected.
Does Tor have enough sockets available?
Ought to, though it has spiked at around 16k sockets used (which is strangely close to 50% of the max number, might be a time to increase that )
Fileno is set at 32k, and it's averaging around 5.5k sockets in use.
Does it warn you about any other potential performance issues in its logs?
Nope.
Have you tried running 2 Tor instances per IPv4 address?
Previously, currently only one to see what throughput we could get a single Tor exit at.
Also, have you tried searching the mailing list archives?
Yes, I've been subscribed for a few years, and I've run relays for a while.
This question gets asked and answered at least once a month.
It's actually seldom discussed how to scale and what the limiting factors are for _Exit_ relays. It's fairly common to hear about relays / Guards and the rampup there.
//D.S

17 MBytes/s in each direction.
From Atlas graph, your node is currently growing up, so wait few weeks more to have the real bandwidth consumption, but don’t expect huge change.
17M*B*ps is 140M*b*ps and you already have a good relay :) This is around the speed expected for standard CPU (150 to 300Mbps per Tor instance, best CPU available can "only" drain around 500Mbps).
And your CPU have all chance to be the bottleneck at this speed. Tor is not multi-core at the moment and so you can’t be able to fully use your CPU capacity. For example, if you have a 4-core CPU, don’t expect to have more than 0.25-0.3 load with only Tor (1 core fully used).
You have to start another Tor instance to use a little more your CPU (1 other core) and so to drain additionnal 150-300Mbps.
Regards,

So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
How long has the relay been up?
4 years or so. ( current uptime: 11 hours since reboot, it reboots weekly )
This relay (5989521A) has been first seen on 2014-04-10 according to https://onionoo.torproject.org (still long enough).
Why do you reboot weekly? Memory leak workaround?
Aeris wrote:
From Atlas graph, your node is currently growing up, so wait few weeks more to have the real bandwidth consumption
Wondering what caused that improvement? (significantly doing better since the last longer downtime on 2016-09-04?)
Where is it located?
Sweden, Tele2 AS
You are apparently the only exit relay in your AS, thanks for running it there!
Have you tried running 2 Tor instances per IPv4 address?
Previously, currently only one to see what throughput we could get a single Tor exit at.
OK, so this email is about speed optimizations of a single tor instance and not about increasing usage a tor exit server?
On 22 Sep 2016, at 05:41, nusenu nusenu@openmailbox.org wrote:
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
In my experience, a single Tor instance can use between 100Mbps and 500Mbps. It's highly dependent on the processor, OpenSSL version, and various network factors.
There are also some random factors in the bandwidth measurement process, including the pair selection for bandwidth measurement. And clients also choose paths randomly. This means some relays get more bandwidth than others by chance.
If you want to use the full capacity of your Exit, run multiple Tor instances. You can run 2 instances per IPv4 address, using different ports. Many people choose ORPort 443 and DirPort 80 as their secondary instance ports (this can help clients on networks that only allow those ports), but you can choose any ports you want.
Have you considered configuring an IPv6 ORPort as well? (It's unlikely to affect traffic, but it will help clients that prefer IPv6.)
How long has the relay been up?
4 years or so. ( current uptime: 11 hours since reboot, it reboots weekly )
This relay (5989521A) has been first seen on 2014-04-10 according to https://onionoo.torproject.org (still long enough).
Why do you reboot weekly? Memory leak workaround?
If you reboot weekly, you will take time each week to re-gain consensus weight and various other flags. For example, you will only have the HSDir flag for ~50% of the time. (The Guard flag is also affected, but it's somewhat irrelevant for Exits.)
I'd avoid the reboots if you can, there's a known bug affecting at least the Guard flag and restarts, where a long-lived stable relays are disproportionately impacted compared with new relays. I haven't seen any evidence that it affects other flags or consensus weight, but you could try not restarting and see if that helps.
...
Have you tried running 2 Tor instances per IPv4 address?
Previously, currently only one to see what throughput we could get a single Tor exit at.
OK, so this email is about speed optimizations of a single tor instance and not about increasing usage a tor exit server?
Tor is not entirely multi-threaded yet. We still recommend running multiple instances on connections faster than 100 - 300Mbps. (And the Tor network currently only uses about 40% of capacity anyway, slightly more on Exits - this utilisation level helps keep latency low.) Later versions have better multithreading and crypto optimisations - thanks for keeping your relay up-to-date.
Tim
Tim Wilson-Brown (teor)
teor2345 at gmail dot com PGP C855 6CED 5D90 A0C5 29F6 4D43 450C BA7F 968F 094B ricochet:ekmygaiu4rzgsk6n xmpp: teor at torproject dot org
On tor, 2016-09-22 at 06:29 +1000, teor wrote:
On 22 Sep 2016, at 05:41, nusenu nusenu@openmailbox.org wrote:
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
In my experience, a single Tor instance can use between 100Mbps and 500Mbps. It's highly dependent on the processor, OpenSSL version, and various network factors.
Acknowledged, the question is, how do you measure that.
There are also some random factors in the bandwidth measurement process, including the pair selection for bandwidth measurement. And clients also choose paths randomly. This means some relays get more bandwidth than others by chance.
That's interesting, how does the bandwidth scaling / metering work? Where/how does it decide how much bandwidth is available vs. what it announces to the world?
Right now I can comfortable pull/push 700Mbit in either direction on this node, so that's where I left the setting, if there is a penalty for stating more bandwidth avialable than the network can measure, then I have a problem.
If you want to use the full capacity of your Exit, run multiple Tor instances.
You can run 2 instances per IPv4 address, using different ports. Many people choose ORPort 443 and DirPort 80 as their secondary instance ports (this can help clients on networks that only allow those ports), but you can choose any ports you want.
True, but there's a limit to how many nodes you can have in a /24, and I really want scaling up on a single node before adding more resources.
Throw more resources at it cause we don't know why it sucks seems like such a devops thing to do.
Have you considered configuring an IPv6 ORPort as well? (It's unlikely to affect traffic, but it will help clients that prefer IPv6.)
Not sure right now, I've had _horrid_ experiences with running Tor on ipv6, ranging from the absurd ( Needing ipv4 configured to set up ipv6) to the inane ( Config keys named "Port" not valid for both ipv6 and ipv4, horrid documentation)
I've got quite a few ipv6 -only- networks, and I'd gladly put up a number of relays/Exits there ( using ephemeral addressing) however that's impossible last I tried it.
My general consensus from last I looked in depth at this is that "Tor doesn't support ipv6. It claims to, but it doesn't."
How long has the relay been up?
4 years or so. ( current uptime: 11 hours since reboot, it reboots weekly )
This relay (5989521A) has been first seen on 2014-04-10 according to https://onionoo.torproject.org (still long enough).
Why do you reboot weekly? Memory leak workaround?
If you reboot weekly, you will take time each week to re-gain consensus weight and various other flags. For example, you will only have the HSDir flag for ~50% of the time. (The Guard flag is also affected, but it's somewhat irrelevant for Exits.)
Fancy that. "Don't upgrade your software because our software can't handle it" is one of those things that really bug me.
How much downtime can the node have before losing consensus weight/flags? Is it just for restarting the tor process as well?
I'd avoid the reboots if you can, there's a known bug affecting at least the Guard flag and restarts, where a long-lived stable relays are disproportionately impacted compared with new relays. I haven't seen any evidence that it affects other flags or consensus weight, but you could try not restarting and see if that helps.
Right, I can tune that for a week and see.
...
Have you tried running 2 Tor instances per IPv4 address?
Previously, currently only one to see what throughput we could get a single Tor exit at.
OK, so this email is about speed optimizations of a single tor instance and not about increasing usage a tor exit server?
Tor is not entirely multi-threaded yet. We still recommend running multiple instances on connections faster than 100 - 300Mbps. (And the Tor network currently only uses about 40% of capacity anyway, slightly more on Exits - this utilisation level helps keep latency low.) Later versions have better multithreading and crypto optimisations - thanks for keeping your relay up-to-date.
Tim
Tim Wilson-Brown (teor)
teor2345 at gmail dot com PGP C855 6CED 5D90 A0C5 29F6 4D43 450C BA7F 968F 094B ricochet:ekmygaiu4rzgsk6n xmpp: teor at torproject dot org
tor-relays mailing list tor-relays@lists.torproject.org https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-relays
Hi,
I wanted to highlight the following parts of my reply:
The Tor network is quite happy to allocate around 47 MByte/s (yes, 376 MBit/s) to your relay based on its bandwidth measurements, but it won't do that until your relay shows it is actually capable of sustaining that traffic over a 10-second period (the observed bandwidth). At the moment, your relay can only do 19.83 MByte/s, so that's what it's being allocated.
Maybe your provider has good connectivity to the bandwidth authorities, but bad connectivity elsewhere? Maybe your provider is otherwise limiting output traffic?
Do you run a local, caching, DNS resolver? That could be a bottleneck, as almost all of your observed bandwidth is based on exit traffic.
The details are below:
On 22 Sep 2016, at 03:58, D. S. Ljungmark spider@takeit.se wrote:
On tor, 2016-09-22 at 06:29 +1000, teor wrote:
On 22 Sep 2016, at 05:41, nusenu nusenu@openmailbox.org wrote:
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
In my experience, a single Tor instance can use between 100Mbps and 500Mbps. It's highly dependent on the processor, OpenSSL version, and various network factors.
Acknowledged, the question is, how do you measure that.
There's a tool called "chutney" that can calculate an effective local bandwidth based on how fast a Tor test network can transmit data. Using it, I discovered that two machines that were meant to be almost identical had approximately 1.5 Gbps and 500 Mbps capacity, because one had a slightly older processor.
This is how I test the local CPU capacity for Tor's crypto:
git clone https://git.torproject.org/chutney.git chutney/tools/test-network.sh --flavor basic-min --data 10000000
This is how I test the local file descriptor and other kernel data structure capacity:
chutney/tools/test-network.sh --flavor basic-025
This is how I test what a single client can push through a Tor Exit (I think Exits limit each client to a certain amount of bandwidth, but I'm not sure - maybe it's 1 Mbit/s or 1 MByte/s):
tor DataDirectory /tmp/tor.$$ PidFile /tmp/tor.$$/tor.pid SOCKSPort 2000 ExitNodes <your-exit-1> sleep 10 curl --socks5-hostname 127.0.0.1:"$1" <a-large-download-url-here>
There are also some random factors in the bandwidth measurement process, including the pair selection for bandwidth measurement. And clients also choose paths randomly. This means some relays get more bandwidth than others by chance.
That's interesting, how does the bandwidth scaling / metering work? Where/how does it decide how much bandwidth is available vs. what it announces to the world?
Tor has 5 bandwidth authorities that measure each relay around twice per week. Then the median measurement is used for the consensus weight, which is the weight clients use to choose relays. (The relay's observed bandwidth is also used to limit the consensus weight.)
In particular, your relay is currently limited by its observed bandwidth of 19.83 MByte/s. Mouse over the "Advertised Bandwidth" figure to check: https://atlas.torproject.org/#details/5989521A85C94EE101E88B8DB2E68321673F94...
The gory details of each bandwidth authority's vote are in: https://collector.torproject.org/recent/relay-descriptors/votes/
Faravahar Bandwidth=10000 Measured=43800 gabelmoo Bandwidth=10000 Measured=78200 moria1 Bandwidth=10000 Measured=47200 maatuska Bandwidth=10000 Measured=40100 longclaw Bandwidth=10000 Measured=49500
(I usually look these up by hand, but I'm sure there's a faster way to do it using stem.)
So the Tor network is quite happy to allocate around 47 MByte/s (yes, 376 MBit/s) to your relay based on its bandwidth measurements, but it won't do that until your relay shows it is actually capable of sustaining that traffic over a 10-second period (the observed bandwidth). At the moment, your relay can only do 19.83 MByte/s, so that's what it's being allocated.
Maybe your provider has good connectivity to the bandwidth authorities, but bad connectivity elsewhere? Maybe your provider is otherwise limiting output traffic?
Do you run a local, caching, DNS resolver? That could be a bottleneck, as almost all of your observed bandwidth is based on exit traffic.
Right now I can comfortable pull/push 700Mbit in either direction on this node, so that's where I left the setting, if there is a penalty for stating more bandwidth avialable than the network can measure, then I have a problem.
No, the network agrees with your setting - 376 MBit/s / 40% average Tor network utilisation is 940 Mbps. (It's slightly higher than your actual bandwidth, possibly because it's an exit, or in a well-connected network position.)
If you want to use the full capacity of your Exit, run multiple Tor instances.
You can run 2 instances per IPv4 address, using different ports. Many people choose ORPort 443 and DirPort 80 as their secondary instance ports (this can help clients on networks that only allow those ports), but you can choose any ports you want.
True, but there's a limit to how many nodes you can have in a /24, and I really want scaling up on a single node before adding more resources.
No there's not, not for a /24. You can have 253 * 2 = 506 Tor instances in an IPv4 /24.
Throw more resources at it cause we don't know why it sucks seems like such a devops thing to do.
Add another instance on the same machine. Not more resources, but more processes, more threads using the existing resources.
Have you considered configuring an IPv6 ORPort as well? (It's unlikely to affect traffic, but it will help clients that prefer IPv6.)
Not sure right now, I've had _horrid_ experiences with running Tor on ipv6, ranging from the absurd ( Needing ipv4 configured to set up ipv6)
IPv4 addresses are mandatory for relays for a few reasons: * Tor assumes that relays form a fully-connected clique - this isn't possible if some are IPv4-only and some are IPv6-only; * some of Tor's protocols only send an IPv4 address - they're being redesigned, but protocol upgrades are hard; * until recently, clients could only bootstrap over IPv4 (and they still can't using microdescriptors, only full descriptors); * and IPv6-only clients have poor anonymity, because they stick out too much.
to the inane ( Config keys named "Port" not valid for both ipv6 and ipv4, horrid documentation)
We're working on the IPv6 documentation, and happy to fix any issues. What particular Port config? What was bad about the documentation?
Feel free to log bugs against Core Tor/Tor, or we can log them for you: https://trac.torproject.org/
I've got quite a few ipv6 -only- networks, and I'd gladly put up a number of relays/Exits there ( using ephemeral addressing) however that's impossible last I tried it.
Yes, it is, see above for why.
My general consensus from last I looked in depth at this is that "Tor doesn't support ipv6. It claims to, but it doesn't."
Choosing anonymous, random paths through a non-clique network (mixed IPv4-only, dual-stack, and IPv6-only) is an open research problem. We can't really implement IPv6-only relays until there are some reasonable solutions to this issue. Until then, we have dual-stack relays.
And IPv6-only Tor clients can connect using IPv6 bridges, or bootstrap over IPv6 with ClientUseIPv4 0 and UseMicrodescriptors 0.
That's pretty much the limit of what we can do with IPv6, until researchers come up with solutions to the non-clique issue.
How long has the relay been up?
4 years or so. ( current uptime: 11 hours since reboot, it reboots weekly )
This relay (5989521A) has been first seen on 2014-04-10 according to https://onionoo.torproject.org (still long enough).
Why do you reboot weekly? Memory leak workaround?
If you reboot weekly, you will take time each week to re-gain consensus weight and various other flags. For example, you will only have the HSDir flag for ~50% of the time. (The Guard flag is also affected, but it's somewhat irrelevant for Exits.)
Fancy that. "Don't upgrade your software because our software can't handle it" is one of those things that really bug me.
That's not what I said. Upgrade your software. Have your relay go up and down as much as you like. The network will handle it fine. Tor clients will be fine.
But if you want to optimise your traffic, then fewer restarts are one thing to try. A restart per week certainly isn't typical of most Tor relays, so your relay looks less stable by comparison.
How much downtime can the node have before losing consensus weight/flags?
A restart loses the HSDir flag for 72 hours, and the Guard flag for a period that is dependent on how old your relay is. (It should be inversely related, currently it seems to be positively correlated, which is a bug we're working on fixing.)
Is it just for restarting the tor process as well?
Yes. Try sending it a HUP instead, when you've just changed the config.
Why do you (need to) restart weekly?
I'd avoid the reboots if you can, there's a known bug affecting at least the Guard flag and restarts, where a long-lived stable relays are disproportionately impacted compared with new relays. I haven't seen any evidence that it affects other flags or consensus weight, but you could try not restarting and see if that helps.
Right, I can tune that for a week and see.
Thanks. Hope it works out for you.
Tim
Tim Wilson-Brown (teor)
teor2345 at gmail dot com PGP C855 6CED 5D90 A0C5 29F6 4D43 450C BA7F 968F 094B ricochet:ekmygaiu4rzgsk6n xmpp: teor at torproject dot org
On Thu, Sep 22, 2016 at 6:30 PM, teor teor2345@gmail.com wrote:
Hi,
I wanted to highlight the following parts of my reply:
The Tor network is quite happy to allocate around 47 MByte/s (yes, 376 MBit/s) to your relay based on its bandwidth measurements, but it won't do that until your relay shows it is actually capable of sustaining that traffic over a 10-second period (the observed bandwidth). At the moment, your relay can only do 19.83 MByte/s, so that's what it's being allocated.
Maybe your provider has good connectivity to the bandwidth authorities, but bad connectivity elsewhere? Maybe your provider is otherwise limiting output traffic?
The provider shouldn't be throttling/limiting. There are other consumers on the net, and I've been able to maintain long-term high volume traffic so far without it.
Do you run a local, caching, DNS resolver? That could be a bottleneck, as almost all of your observed bandwidth is based on exit traffic.
Now that is something I can try to replace, Thank you, I'll look into that.
The details are below:
On 22 Sep 2016, at 03:58, D. S. Ljungmark spider@takeit.se wrote:
On tor, 2016-09-22 at 06:29 +1000, teor wrote:
On 22 Sep 2016, at 05:41, nusenu nusenu@openmailbox.org wrote:
> > So, how do we get tor to move past 100-200Mbit? Is it just a > waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
In my experience, a single Tor instance can use between 100Mbps and 500Mbps. It's highly dependent on the processor, OpenSSL version, and various network factors.
Acknowledged, the question is, how do you measure that.
Thank you, I'll look further into this during this upcoming week.
There's a tool called "chutney" that can calculate an effective local bandwidth based on how fast a Tor test network can transmit data. Using it, I discovered that two machines that were meant to be almost identical had approximately 1.5 Gbps and 500 Mbps capacity, because one had a slightly older processor.
This is how I test the local CPU capacity for Tor's crypto:
git clone https://git.torproject.org/chutney.git chutney/tools/test-network.sh --flavor basic-min --data 10000000
This is how I test the local file descriptor and other kernel data structure capacity:
chutney/tools/test-network.sh --flavor basic-025
This is how I test what a single client can push through a Tor Exit (I think Exits limit each client to a certain amount of bandwidth, but I'm not sure - maybe it's 1 Mbit/s or 1 MByte/s):
tor DataDirectory /tmp/tor.$$ PidFile /tmp/tor.$$/tor.pid SOCKSPort 2000 ExitNodes <your-exit-1> sleep 10 curl --socks5-hostname 127.0.0.1:"$1" <a-large-download-url-here>
There are also some random factors in the bandwidth measurement process, including the pair selection for bandwidth measurement. And clients also choose paths randomly. This means some relays get more bandwidth than others by chance.
That's interesting, how does the bandwidth scaling / metering work? Where/how does it decide how much bandwidth is available vs. what it announces to the world?
Tor has 5 bandwidth authorities that measure each relay around twice per week. Then the median measurement is used for the consensus weight, which is the weight clients use to choose relays. (The relay's observed bandwidth is also used to limit the consensus weight.)
In particular, your relay is currently limited by its observed bandwidth of 19.83 MByte/s. Mouse over the "Advertised Bandwidth" figure to check: https://atlas.torproject.org/#details/5989521A85C94EE101E88B8DB2E68321673F94...
The gory details of each bandwidth authority's vote are in: https://collector.torproject.org/recent/relay-descriptors/votes/
Faravahar Bandwidth=10000 Measured=43800 gabelmoo Bandwidth=10000 Measured=78200 moria1 Bandwidth=10000 Measured=47200 maatuska Bandwidth=10000 Measured=40100 longclaw Bandwidth=10000 Measured=49500
(I usually look these up by hand, but I'm sure there's a faster way to do it using stem.)
So the Tor network is quite happy to allocate around 47 MByte/s (yes, 376 MBit/s) to your relay based on its bandwidth measurements, but it won't do that until your relay shows it is actually capable of sustaining that traffic over a 10-second period (the observed bandwidth). At the moment, your relay can only do 19.83 MByte/s, so that's what it's being allocated.
That's some interesting numbers, and they sort of go against what I've seen so far on the measures. Except for a few spikes where I've seen 16k sockets allocated at once, I'm not sure where.
Maybe your provider has good connectivity to the bandwidth authorities, but bad connectivity elsewhere?
Could be, I'm not in control of peering.
Maybe your provider is otherwise limiting output traffic?
Shouldn't be, at least not with the measures I've done elsewhere. ( iperf and similar )
Do you run a local, caching, DNS resolver? That could be a bottleneck, as almost all of your observed bandwidth is based on exit traffic.
Right now I can comfortable pull/push 700Mbit in either direction on this node, so that's where I left the setting, if there is a penalty for stating more bandwidth avialable than the network can measure, then I have a problem.
No, the network agrees with your setting - 376 MBit/s / 40% average Tor network utilisation is 940 Mbps. (It's slightly higher than your actual bandwidth, possibly because it's an exit, or in a well-connected network position.)
Okay, that's good to know.
If you want to use the full capacity of your Exit, run multiple Tor instances.
You can run 2 instances per IPv4 address, using different ports. Many people choose ORPort 443 and DirPort 80 as their secondary instance ports (this can help clients on networks that only allow those ports), but you can choose any ports you want.
True, but there's a limit to how many nodes you can have in a /24, and I really want scaling up on a single node before adding more resources.
No there's not, not for a /24. You can have 253 * 2 = 506 Tor instances in an IPv4 /24.
Throw more resources at it cause we don't know why it sucks seems like such a devops thing to do.
Add another instance on the same machine. Not more resources, but more processes, more threads using the existing resources.
Have you considered configuring an IPv6 ORPort as well? (It's unlikely to affect traffic, but it will help clients that prefer IPv6.)
Not sure right now, I've had _horrid_ experiences with running Tor on ipv6, ranging from the absurd ( Needing ipv4 configured to set up ipv6)
IPv4 addresses are mandatory for relays for a few reasons:
- Tor assumes that relays form a fully-connected clique - this isn't possible if some are IPv4-only and some are IPv6-only;
- some of Tor's protocols only send an IPv4 address - they're being redesigned, but protocol upgrades are hard;
- until recently, clients could only bootstrap over IPv4 (and they still can't using microdescriptors, only full descriptors);
- and IPv6-only clients have poor anonymity, because they stick out too much.
to the inane ( Config keys named "Port" not valid for both ipv6 and ipv4, horrid documentation)
We're working on the IPv6 documentation, and happy to fix any issues. What particular Port config? What was bad about the documentation?
DirPort tor.modio.se:888 won't actually bind on ipv6, even when it's resolving to both ipv4 and ipv6
DirPort 888 ; won't actually bind on ipv6. DirPort [::]:888; Won't actually bind on ipv6
Adding more DirPort statements means that you have to pick and choose, ipv6 or ipv4. Can only broadcast one.
ORPort same as above.
Having to actually hard-code ipv6 (in the dynamic nature that it is) in the config files is a pure failure, and I ended up writing a way too annoying template file to fill it in a boot, simply because Tor can't bind to a port when it's told.
Feel free to log bugs against Core Tor/Tor, or we can log them for you: https://trac.torproject.org/
I've got quite a few ipv6 -only- networks, and I'd gladly put up a number of relays/Exits there ( using ephemeral addressing) however that's impossible last I tried it.
Yes, it is, see above for why.
My general consensus from last I looked in depth at this is that "Tor doesn't support ipv6. It claims to, but it doesn't."
Choosing anonymous, random paths through a non-clique network (mixed IPv4-only, dual-stack, and IPv6-only) is an open research problem. We can't really implement IPv6-only relays until there are some reasonable solutions to this issue. Until then, we have dual-stack relays.
And IPv6-only Tor clients can connect using IPv6 bridges, or bootstrap over IPv6 with ClientUseIPv4 0 and UseMicrodescriptors 0.
That's pretty much the limit of what we can do with IPv6, until researchers come up with solutions to the non-clique issue.
You can fix the daemon to actually be capable of binding to ports, and to not require us to jump through annoying settings just to get it to even _listen_ to ipv6.
How long has the relay been up?
4 years or so. ( current uptime: 11 hours since reboot, it reboots weekly )
This relay (5989521A) has been first seen on 2014-04-10 according to https://onionoo.torproject.org (still long enough).
Why do you reboot weekly? Memory leak workaround?
If you reboot weekly, you will take time each week to re-gain consensus weight and various other flags. For example, you will only have the HSDir flag for ~50% of the time. (The Guard flag is also affected, but it's somewhat irrelevant for Exits.)
Fancy that. "Don't upgrade your software because our software can't handle it" is one of those things that really bug me.
That's not what I said. Upgrade your software. Have your relay go up and down as much as you like. The network will handle it fine. Tor clients will be fine.
But if you want to optimise your traffic, then fewer restarts are one thing to try. A restart per week certainly isn't typical of most Tor relays, so your relay looks less stable by comparison.
Right, I've readjusted that setting, let's see if that fixes anything here, we'll see after a month or so I guess.
How much downtime can the node have before losing consensus weight/flags?
A restart loses the HSDir flag for 72 hours, and the Guard flag for a period that is dependent on how old your relay is. (It should be inversely related, currently it seems to be positively correlated, which is a bug we're working on fixing.)
Is it just for restarting the tor process as well?
Yes. Try sending it a HUP instead, when you've just changed the config.
HUP appearantly isn't enough to not make it restart when it's resolving addresses on ipv4/ipv6. Turns out its closing sockets first, then resolving the domainnames, realizing it can't listen, and then stop.
Why do you (need to) restart weekly?
Same schedule as all infra. We've got a weekly maintainance (well, two) for restarting machines. Tests recovery, failover and similar. Not perfect, but better than being afraid of restarting.
I'd avoid the reboots if you can, there's a known bug affecting at least the Guard flag and restarts, where a long-lived stable relays are disproportionately impacted compared with new relays. I haven't seen any evidence that it affects other flags or consensus weight, but you could try not restarting and see if that helps.
Right, I can tune that for a week and see.
Thanks. Hope it works out for you.
Me too, I'm hoping to see what the heck is going on to get a stable load before I start adding more relays/exits.
The performance characteristics of an exit are... not very well documented.
On 22 Sep 2016, at 11:55, Dennis Ljungmark spider@takeit.se wrote:
On Thu, Sep 22, 2016 at 6:30 PM, teor teor2345@gmail.com wrote:
...
Have you considered configuring an IPv6 ORPort as well? (It's unlikely to affect traffic, but it will help clients that prefer IPv6.)
Not sure right now, I've had _horrid_ experiences with running Tor on ipv6, ranging from the absurd ( Needing ipv4 configured to set up ipv6)
IPv4 addresses are mandatory for relays for a few reasons:
- Tor assumes that relays form a fully-connected clique - this isn't possible if some are IPv4-only and some are IPv6-only;
- some of Tor's protocols only send an IPv4 address - they're being redesigned, but protocol upgrades are hard;
- until recently, clients could only bootstrap over IPv4 (and they still can't using microdescriptors, only full descriptors);
- and IPv6-only clients have poor anonymity, because they stick out too much.
to the inane ( Config keys named "Port" not valid for both ipv6 and ipv4, horrid documentation)
We're working on the IPv6 documentation, and happy to fix any issues. What particular Port config? What was bad about the documentation?
DirPort tor.modio.se:888 won't actually bind on ipv6, even when it's resolving to both ipv4 and ipv6
On most OSs, you can only bind to one IP address per socket. Tor tends to choose the IPv4 address when resolving domain names, because it's what most operators want.
So I'd encourage you to use an explicit IPv4 or IPv6 address. Tor tries not to depend too much on DNS, because it's not particularly secure in general.
DirPort 888 ; won't actually bind on ipv6. DirPort [::]:888; Won't actually bind on ipv6
The binding does work with explicit IPv4 and IPv6 addresses.
But an IPv6 DirPort will never be used by any other Tor client or relay. Clients use the IPv4 or IPv6 ORPort, and relays use the IPv4 DirPort.
We have an open ticket to clarify this in the DirPort documentation.
Adding more DirPort statements means that you have to pick and choose, ipv6 or ipv4. Can only broadcast one.
Yes, the relay descriptor syntax only supports one IPv4 address, with one DirPort. However, it is possible to supply an IPv6 ORPort using an explicit IPv6 address.
ORPort same as above.
Have you tried explicit IPv4 or IPv6 addresses?
Having to actually hard-code ipv6 (in the dynamic nature that it is) in the config files is a pure failure, and I ended up writing a way too annoying template file to fill it in a boot, simply because Tor can't bind to a port when it's told.
The current default is IPv4 0.0.0.0, as documented in the ORListenAddress man page entry.
Tor doesn't detect your IPv6 address at the moment, so you have to supply it explicitly. There's an open ticket for that, but address autodetection is fraught with confusion. We really do encourage operators to provide explicit, known stable addresses.
Although it looks like we could also improve the resolution and binding when relay operators supply a domain name. Feel free to open a ticket with the issues that you're seeing: https://trac.torproject.org/
My general consensus from last I looked in depth at this is that "Tor doesn't support ipv6. It claims to, but it doesn't."
Choosing anonymous, random paths through a non-clique network (mixed IPv4-only, dual-stack, and IPv6-only) is an open research problem. We can't really implement IPv6-only relays until there are some reasonable solutions to this issue. Until then, we have dual-stack relays.
And IPv6-only Tor clients can connect using IPv6 bridges, or bootstrap over IPv6 with ClientUseIPv4 0 and UseMicrodescriptors 0.
That's pretty much the limit of what we can do with IPv6, until researchers come up with solutions to the non-clique issue.
You can fix the daemon to actually be capable of binding to ports, and to not require us to jump through annoying settings just to get it to even _listen_ to ipv6.
IPv6 DirPorts are not used.
IPv6 ORPorts work like this:
ORPort [IPv6 address]:Port
I'm not sure what we could improve, given that the operator really needs to nominate a stable IPv6 address.
How much downtime can the node have before losing consensus weight/flags?
A restart loses the HSDir flag for 72 hours, and the Guard flag for a period that is dependent on how old your relay is. (It should be inversely related, currently it seems to be positively correlated, which is a bug we're working on fixing.)
Is it just for restarting the tor process as well?
Yes. Try sending it a HUP instead, when you've just changed the config.
HUP appearantly isn't enough to not make it restart when it's resolving addresses on ipv4/ipv6. Turns out its closing sockets first, then resolving the domainnames, realizing it can't listen, and then stop.
Yes, there's an open ticket for one case where 0.0.0.0 and a particular IPv4 address overlap. You might have just discovered another one.
I'd encourage you to log a ticket with more detail at: https://trac.torproject.org/
Or, if you let me know a few more details, I can log one for you. What's the config? What are the log messages?
I'd avoid the reboots if you can, there's a known bug affecting at least the Guard flag and restarts, where a long-lived stable relays are disproportionately impacted compared with new relays. I haven't seen any evidence that it affects other flags or consensus weight, but you could try not restarting and see if that helps.
Right, I can tune that for a week and see.
Thanks. Hope it works out for you.
Me too, I'm hoping to see what the heck is going on to get a stable load before I start adding more relays/exits.
The performance characteristics of an exit are... not very well documented.
Typically, exit bandwidth is rare in the Tor network, and tends to be over-utilised. So any issues using Exits to their full potential disproportionately impact Tor users.
We would love some help with investigating and documenting Exit performance!
Tim
Tim Wilson-Brown (teor)
teor2345 at gmail dot com PGP C855 6CED 5D90 A0C5 29F6 4D43 450C BA7F 968F 094B ricochet:ekmygaiu4rzgsk6n xmpp: teor at torproject dot org
On ons, 2016-09-21 at 19:41 +0000, nusenu wrote:
So, how do we get tor to move past 100-200Mbit? Is it just a waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
Mainly, I want to scale up a single exit first, before I start adding more resources.
I've ran some high speed _relays_ in the past, and those are fairly easy, however Exits seem to have a bit of a different behaviour, and exits are what the network really needs more of.
How long has the relay been up?
4 years or so. ( current uptime: 11 hours since reboot, it reboots weekly )
This relay (5989521A) has been first seen on 2014-04-10 according to https://onionoo.torproject.org (still long enough).
Might be it, I recently ( see downtime ) had to migrate both to a new provider, and new hardware, and I probably didn't pay attention enough on which of the old relays I brought back.
I got the keys for the others set up, but before I relaunch them, I want a stable performance for the current one.
Why do you reboot weekly? Memory leak workaround?
Upgrade / kernel upgrades. I'd rather see systems interrupted regularly and coming back, than having a headache when they don't come back.
Aeris wrote:
From Atlas graph, your node is currently growing up, so wait few weeks more to have the real bandwidth consumption
Wondering what caused that improvement? (significantly doing better since the last longer downtime on 2016-09-04?)
Me increasing the bandwidth, really. I had a base profile for what the customer network was doing, and decided that we could offer up 600Mbit of traffic for Tor.
Where is it located?
Sweden, Tele2 AS
You are apparently the only exit relay in your AS, thanks for running it there!
Have you tried running 2 Tor instances per IPv4 address?
Previously, currently only one to see what throughput we could get a single Tor exit at.
OK, so this email is about speed optimizations of a single tor instance and not about increasing usage a tor exit server?
This is about the single instance, and about _exit_ tunings past the basic 100Mbit traffic ( which we regularly hit )
Before I re-launch the other relays, I want to be sure that all the settings are tuned on a single one, so they don't end up competing/starving each other for resources.
And while the day-to-day graph of bandwidth/Resources used by the exit are interesting, I'm not seeing any _obvious_ bottlenecks here.
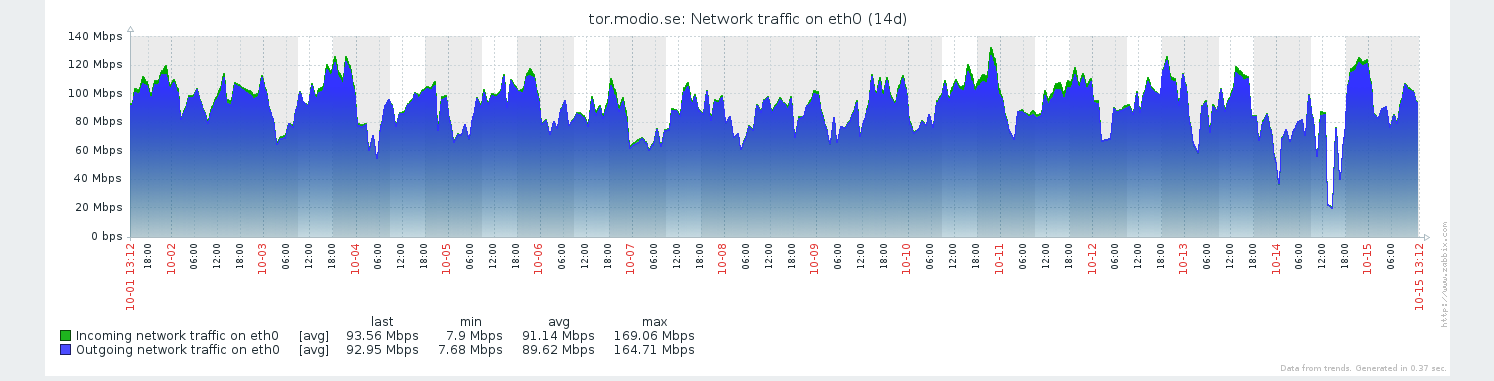
Here's a graph,
As you can see, incoming and outgoing bandwidth match eachother very neatly ( could almost be a single graph,) CPU utilization in user time matches reasonably with this, and the system time is a steady buzz.
What's to notice is the scale on the left side (% cpu usage) , where system load stays below 5%, and user load stays under 15%.
15% user load on a 2-core system to shovel ~ 2*15 Mbyte/s ( Not Mbit, Mbyte).
So, that's why I'm posting here, to figure out _where_ the bottleneck is. Many people have mentioned CPU as an obvious reason, however, I don't see CPU usage actually spiking much on this system.
So, right now I don't really know _why_ I'm not seeing more bandwidth utilization. If CPU, on single core, would be the limiting factor, I'd expect bandwidth to go up to at least 40MByte/s ( scaling linear on CPU usage, at around 70% then ).
So, Those are the raw numbers, and why I'm looking to the list for scaling tips for exits.
It might well be that I've missed something, some tuning I should have remembered ( Like increasing the conntrack hash table size ) but I think I've covered the basics.
//D.S.
> > > So, how do we get tor to move past 100-200Mbit? Is it just a > > > waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
Mainly, I want to scale up a single exit first, before I start adding more resources.
As Aeris, teor and me tried to explain, this is _not_ about "adding more resources", but since you keep ignoring that it is a bit pointless to state that over and over again.
teor gave some rather comprehensive answers and has said pretty much anything relevant I guess.
In the end it should be about optimizing exit bandwidth cost (many MBit/s for fewer $) no matter how many tor processes it requires to get the most out of your hardware, number of available IPs and uplink connectivity.
It might well be that I've missed something, some tuning I should have remembered ( Like increasing the conntrack hash table size )
I'm not sure I would run a stateful firewall on an dedicated exit server at all. https://www.torservers.net/wiki/setup/server
So, Now I've taken some steps to adjust the state of the relay, and try to balance this.
To reiterate a point previously, before I start adding more tor daemons or servers to this, I want to know how to scale and optimise what is already there.
- Set up unbound in cache mode rather than use our local network unbound - Disabled on machine firewall (stateful) - Ensured AES acceleration worked - Boosted amount of open files allowed even more - Stopped doing regular reboots and only reboot on kernel change - Bound Tor to a single core
The exit is till this one: https://atlas.torproject.org/#details/5989521A85C94EE101E88B8DB2E68321673F94...
CPU utilization of a single core on the machine never goes > 22%
Thus while it may be CPU bound, it's never maximising the CPU usage.
CPU and network are still scaling together with each other.
Load ( not cpu usage) is fairly stable and load1 hasn't gone > 0.2
It's holding between 5k and 16k sockets in use, and ~3.5k sockets in TIME_WAIT state. (Fairly high amount?)
So far, I'm not sure _why_ it's capping itself on bandwidth, and that's the one thing that I want to figure out before I start scaling out horizontally.
On Fri, Sep 23, 2016 at 11:28 AM, nusenu nusenu@openmailbox.org wrote:
> > > > So, how do we get tor to move past 100-200Mbit? Is it just a > > > > waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
Mainly, I want to scale up a single exit first, before I start adding more resources.
As Aeris, teor and me tried to explain, this is _not_ about "adding more resources", but since you keep ignoring that it is a bit pointless to state that over and over again.
teor gave some rather comprehensive answers and has said pretty much anything relevant I guess.
In the end it should be about optimizing exit bandwidth cost (many MBit/s for fewer $) no matter how many tor processes it requires to get the most out of your hardware, number of available IPs and uplink connectivity.
It might well be that I've missed something, some tuning I should have remembered ( Like increasing the conntrack hash table size )
I'm not sure I would run a stateful firewall on an dedicated exit server at all. https://www.torservers.net/wiki/setup/server
tor-relays mailing list tor-relays@lists.torproject.org https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-relays

{kind=link}
{kind=link}
On 25 Oct. 2016, at 22:26, D.S. Ljungmark ljungmark@modio.se wrote:
So, Now I've taken some steps to adjust the state of the relay, and try to balance this.
To reiterate a point previously, before I start adding more tor daemons or servers to this, I want to know how to scale and optimise what is already there.
- Set up unbound in cache mode rather than use our local network unbound
- Disabled on machine firewall (stateful)
- Ensured AES acceleration worked
- Boosted amount of open files allowed even more
- Stopped doing regular reboots and only reboot on kernel change
- Bound Tor to a single core
Tor is multi-process, so I wouldn't recommend binding it and its cpuworkers to the same core. That could degrade performance.
The exit is till this one: https://atlas.torproject.org/#details/5989521A85C94EE101E88B8DB2E68321673F94...
CPU utilization of a single core on the machine never goes > 22%
Thus while it may be CPU bound, it's never maximising the CPU usage.
CPU and network are still scaling together with each other.
Load ( not cpu usage) is fairly stable and load1 hasn't gone > 0.2
It's holding between 5k and 16k sockets in use,
Having connections to 6000 relays is normal, and then there are more sockets for Exit traffic.
and ~3.5k sockets in TIME_WAIT state. (Fairly high amount?)
Quite normal for an Exit.
So far, I'm not sure _why_ it's capping itself on bandwidth, and that's the one thing that I want to figure out before I start scaling out horizontally.
If you hover over the Advertised Bandwidth in atlas, your relay's advertised bandwidth is equal to its observed bandwidth.
Your relay's observed bandwidth is listed as 19.98 MByte / second in its descriptor: http://193.15.16.4:9030/tor/server/authority
The bandwidth authorities seem to think your relay can handle twice that, nominally 38100 KByte / second: https://consensus-health.torproject.org/consensus-health-2016-10-25-10-00.ht... (This is a large page)
Last time we emailed, your relay's observed bandwidth was 19.83 MByte / second. This is suspiciously stable. Your observed bandwidth should vary a lot more. But it seems capped at 20 MByte / second.
Perhaps your network link throttles traffic.
Or, the throttling is happening via CPU limiting.
Or, you have an option set that is limiting Tor's bandwidth usage directly.
Did you ever try using chutney to measure your local bandwidth? That will tell you what your CPU is capable of. (Leaving you to distinguish between config and network.)
Alternately, set up a relay with the same config at another provider.
Or, set up a relay with the same config on the same machine.
Or, set up a relay with a minimal config on the same machine. (Try commenting-out lines in the config one at a time. Start with RelayBandwidthRate and RelayBandwidthBurst.)
But other relays achieve much faster speeds, so it's likely something unique to your situation.
Tim
On Fri, Sep 23, 2016 at 11:28 AM, nusenu nusenu@openmailbox.org wrote:
>>>>> So, how do we get tor to move past 100-200Mbit? Is it just a >>>>> waiting game?
I'd say just run more instances if you still have resources left and want to contribute more bw. (obviously also your exit policy influences on how much your instance is used)
Mainly, I want to scale up a single exit first, before I start adding more resources.
As Aeris, teor and me tried to explain, this is _not_ about "adding more resources", but since you keep ignoring that it is a bit pointless to state that over and over again.
teor gave some rather comprehensive answers and has said pretty much anything relevant I guess.
In the end it should be about optimizing exit bandwidth cost (many MBit/s for fewer $) no matter how many tor processes it requires to get the most out of your hardware, number of available IPs and uplink connectivity.
It might well be that I've missed something, some tuning I should have remembered ( Like increasing the conntrack hash table size )
I'm not sure I would run a stateful firewall on an dedicated exit server at all. https://www.torservers.net/wiki/setup/server
tor-relays mailing list tor-relays@lists.torproject.org https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-relays
tor-relays mailing list tor-relays@lists.torproject.org https://lists.torproject.org/cgi-bin/mailman/listinfo/tor-relays
T
On tis, 2016-10-25 at 22:52 +1100, teor wrote:
On 25 Oct. 2016, at 22:26, D.S. Ljungmark ljungmark@modio.se wrote:
So, Now I've taken some steps to adjust the state of the relay, and try to balance this.
To reiterate a point previously, before I start adding more tor daemons or servers to this, I want to know how to scale and optimise what is already there.
- Set up unbound in cache mode rather than use our local network
unbound
- Disabled on machine firewall (stateful)
- Ensured AES acceleration worked
- Boosted amount of open files allowed even more
- Stopped doing regular reboots and only reboot on kernel change
- Bound Tor to a single core
Tor is multi-process, so I wouldn't recommend binding it and its cpuworkers to the same core. That could degrade performance.
Acknowledged, but it does allow me to bind other things (unbound, interrupts) to other cpus, which was part of the reasoning here.
The exit is till this one: https://atlas.torproject.org/#details/5989521A85C94EE101E88B8DB2E68 321673F9405
CPU utilization of a single core on the machine never goes > 22%
Thus while it may be CPU bound, it's never maximising the CPU usage.
CPU and network are still scaling together with each other.
Load ( not cpu usage) is fairly stable and load1 hasn't gone > 0.2
It's holding between 5k and 16k sockets in use,
Having connections to 6000 relays is normal, and then there are more sockets for Exit traffic.
Is 6k normal/high/low for an exit? I'm trying to find the cause of the low performance here.
and ~3.5k sockets in TIME_WAIT state. (Fairly high amount?)
Quite normal for an Exit.
check.
So far, I'm not sure _why_ it's capping itself on bandwidth, and that's the one thing that I want to figure out before I start scaling out horizontally.
If you hover over the Advertised Bandwidth in atlas, your relay's advertised bandwidth is equal to its observed bandwidth.
Your relay's observed bandwidth is listed as 19.98 MByte / second in its descriptor: http://193.15.16.4:9030/tor/server/authority
The bandwidth authorities seem to think your relay can handle twice that, nominally 38100 KByte / second: https://consensus-health.torproject.org/consensus-health-2016-10-25-1 0-00.html#5989521A85C94EE101E88B8DB2E68321673F9405 (This is a large page)
Last time we emailed, your relay's observed bandwidth was 19.83 MByte / second. This is suspiciously stable. Your observed bandwidth should vary a lot more. But it seems capped at 20 MByte / second.
That's exactly the behaviour I see too, which is why I'm spending the time trying to figure this out ( and asking incessant questions )
Normally, I don't see that kind of limitation, so I don't _think_ it's the line, but I can't be sure, of course.
Perhaps your network link throttles traffic.
Possible, would be good to find out.
Or, the throttling is happening via CPU limiting.
Or, you have an option set that is limiting Tor's bandwidth usage directly.
Not as far as I'm aware, the only one I've set on purpouse are BandwidthBurst / BandwidthRate, both to 92MB.
Did you ever try using chutney to measure your local bandwidth? That will tell you what your CPU is capable of. (Leaving you to distinguish between config and network.)
No, will do that now to see.
Alternately, set up a relay with the same config at another provider.
Or, set up a relay with the same config on the same machine.
Or, set up a relay with a minimal config on the same machine. (Try commenting-out lines in the config one at a time. Start with RelayBandwidthRate and RelayBandwidthBurst.)
But other relays achieve much faster speeds, so it's likely something unique to your situation.
That's what I'm afraid of, I'll go play with chutney now then.
//D.S.
On ons, 2016-10-26 at 15:32 +0200, D. S. Ljungmark wrote:
On tis, 2016-10-25 at 22:52 +1100, teor wrote:
On 25 Oct. 2016, at 22:26, D.S. Ljungmark ljungmark@modio.se wrote:
So, Now I've taken some steps to adjust the state of the relay, and try to balance this.
To reiterate a point previously, before I start adding more tor daemons or servers to this, I want to know how to scale and optimise what is already there.
- Set up unbound in cache mode rather than use our local network
unbound
- Disabled on machine firewall (stateful)
- Ensured AES acceleration worked
- Boosted amount of open files allowed even more
- Stopped doing regular reboots and only reboot on kernel change
- Bound Tor to a single core
Tor is multi-process, so I wouldn't recommend binding it and its cpuworkers to the same core. That could degrade performance.
Acknowledged, but it does allow me to bind other things (unbound, interrupts) to other cpus, which was part of the reasoning here.
The exit is till this one: https://atlas.torproject.org/#details/5989521A85C94EE101E88B8DB2E 68 321673F9405
CPU utilization of a single core on the machine never goes > 22%
Thus while it may be CPU bound, it's never maximising the CPU usage.
CPU and network are still scaling together with each other.
Load ( not cpu usage) is fairly stable and load1 hasn't gone > 0.2
It's holding between 5k and 16k sockets in use,
Having connections to 6000 relays is normal, and then there are more sockets for Exit traffic.
Is 6k normal/high/low for an exit? I'm trying to find the cause of the low performance here.
and ~3.5k sockets in TIME_WAIT state. (Fairly high amount?)
Quite normal for an Exit.
check.
So far, I'm not sure _why_ it's capping itself on bandwidth, and that's the one thing that I want to figure out before I start scaling out horizontally.
If you hover over the Advertised Bandwidth in atlas, your relay's advertised bandwidth is equal to its observed bandwidth.
Your relay's observed bandwidth is listed as 19.98 MByte / second in its descriptor: http://193.15.16.4:9030/tor/server/authority
The bandwidth authorities seem to think your relay can handle twice that, nominally 38100 KByte / second: https://consensus-health.torproject.org/consensus-health-2016-10-25 -1 0-00.html#5989521A85C94EE101E88B8DB2E68321673F9405 (This is a large page)
Last time we emailed, your relay's observed bandwidth was 19.83 MByte / second. This is suspiciously stable. Your observed bandwidth should vary a lot more. But it seems capped at 20 MByte / second.
That's exactly the behaviour I see too, which is why I'm spending the time trying to figure this out ( and asking incessant questions )
Normally, I don't see that kind of limitation, so I don't _think_ it's the line, but I can't be sure, of course.
Perhaps your network link throttles traffic.
Possible, would be good to find out.
Or, the throttling is happening via CPU limiting.
Or, you have an option set that is limiting Tor's bandwidth usage directly.
Not as far as I'm aware, the only one I've set on purpouse are BandwidthBurst / BandwidthRate, both to 92MB.
Did you ever try using chutney to measure your local bandwidth? That will tell you what your CPU is capable of. (Leaving you to distinguish between config and network.)
No, will do that now to see.
Chutney in networks/basic-min mode gives me the following on a 500MB transfer
Single Stream Bandwidth: 42.09 MBytes/s Overall tor Bandwidth: 168.38 MBytes/s
Which seems to be in line with where I'd expect things to be CPU wise. Not optimum, but at least twice higher than what I see in reality.
//D.S.
On 27 Oct. 2016, at 00:32, D. S. Ljungmark spider@takeit.se wrote:
On tis, 2016-10-25 at 22:52 +1100, teor wrote:
On 25 Oct. 2016, at 22:26, D.S. Ljungmark ljungmark@modio.se wrote:
So, Now I've taken some steps to adjust the state of the relay, and try to balance this.
To reiterate a point previously, before I start adding more tor daemons or servers to this, I want to know how to scale and optimise what is already there.
... It's holding between 5k and 16k sockets in use,
Having connections to 6000 relays is normal, and then there are more sockets for Exit traffic.
Is 6k normal/high/low for an exit? I'm trying to find the cause of the low performance here.
6K - 7K is expected for any relay, as there are that many relays in the network.
And then an Exit has a socket for every outgoing Internet connection as well.
and ~3.5k sockets in TIME_WAIT state. (Fairly high amount?)
Quite normal for an Exit.
check.
These are likely from short-lived outgoing Exit connections.
Or, the throttling is happening via CPU limiting.
Or, you have an option set that is limiting Tor's bandwidth usage directly.
Not as far as I'm aware, the only one I've set on purpouse are BandwidthBurst / BandwidthRate, both to 92MB.
Clearly you're not hitting these, so you could turn them off.
On 27 Oct. 2016, at 01:31, D. S. Ljungmark spider@takeit.se wrote:
On ons, 2016-10-26 at 15:32 +0200, D. S. Ljungmark wrote:
On tis, 2016-10-25 at 22:52 +1100, teor wrote:
... Did you ever try using chutney to measure your local bandwidth? That will tell you what your CPU is capable of. (Leaving you to distinguish between config and network.)
No, will do that now to see.
Chutney in networks/basic-min mode gives me the following on a 500MB transfer
Single Stream Bandwidth: 42.09 MBytes/s Overall tor Bandwidth: 168.38 MBytes/s
Which seems to be in line with where I'd expect things to be CPU wise. Not optimum, but at least twice higher than what I see in reality.
You probably want the "Overall tor Bandwidth", which is the bandwidth of the stream multiplied by the number of tor instances that it goes through (4: client, guard, middle, exit).
It doesn't account for CPU usage by the python test harness, or the latency in connection establishment, or any other processes on the machine. So it will always read lower.
Have you tried monitoring the reliability of connections through your Exit?
You can run a Tor client with "ExitNodes {fingerprint}", then use Tor Browser through it. This would help you find out the error messages clients are getting (if any).
You can also use this to do a bulk transfer test through your exit, to see if it has any spare bandwidth.
It might also be worth checking what happens to the bandwidth usage on your Exit over the day and week. A tool like vnstat or munin could help here.
(Normally, the tor network has daily and weekly peaks.)
T
On 27/10/16 00:15, teor wrote:
On 27 Oct. 2016, at 00:32, D. S. Ljungmark spider@takeit.se wrote:
On tis, 2016-10-25 at 22:52 +1100, teor wrote:
On 25 Oct. 2016, at 22:26, D.S. Ljungmark ljungmark@modio.se wrote:
So, Now I've taken some steps to adjust the state of the relay, and try to balance this.
To reiterate a point previously, before I start adding more tor daemons or servers to this, I want to know how to scale and optimise what is already there.
... It's holding between 5k and 16k sockets in use,
Having connections to 6000 relays is normal, and then there are more sockets for Exit traffic.
Is 6k normal/high/low for an exit? I'm trying to find the cause of the low performance here.
6K - 7K is expected for any relay, as there are that many relays in the network.
And then an Exit has a socket for every outgoing Internet connection as well.
Okay, then I'm not being constrained by amount of open/allowed sockets/files or similar, that's good.
and ~3.5k sockets in TIME_WAIT state. (Fairly high amount?)
Quite normal for an Exit.
check.
These are likely from short-lived outgoing Exit connections.
True.
Or, the throttling is happening via CPU limiting.
Or, you have an option set that is limiting Tor's bandwidth usage directly.
Not as far as I'm aware, the only one I've set on purpouse are BandwidthBurst / BandwidthRate, both to 92MB.
Clearly you're not hitting these, so you could turn them off.
I could, but I don't want the relay to accidentally get fast and burst too high.
On 27 Oct. 2016, at 01:31, D. S. Ljungmark spider@takeit.se wrote:
On ons, 2016-10-26 at 15:32 +0200, D. S. Ljungmark wrote:
On tis, 2016-10-25 at 22:52 +1100, teor wrote:
... Did you ever try using chutney to measure your local bandwidth? That will tell you what your CPU is capable of. (Leaving you to distinguish between config and network.)
No, will do that now to see.
Chutney in networks/basic-min mode gives me the following on a 500MB transfer
Single Stream Bandwidth: 42.09 MBytes/s Overall tor Bandwidth: 168.38 MBytes/s
Which seems to be in line with where I'd expect things to be CPU wise. Not optimum, but at least twice higher than what I see in reality.
You probably want the "Overall tor Bandwidth", which is the bandwidth of the stream multiplied by the number of tor instances that it goes through (4: client, guard, middle, exit).
It doesn't account for CPU usage by the python test harness, or the latency in connection establishment, or any other processes on the machine. So it will always read lower.
Understood, but the numbers at least seem to indicate something that's closer to what I was expecting, in bandwidth and CPU usage both.
Have you tried monitoring the reliability of connections through your Exit?
No, that should be next on my list, but it'll have to wait until non-office hours.
You can run a Tor client with "ExitNodes {fingerprint}", then use Tor Browser through it. This would help you find out the error messages clients are getting (if any).
You can also use this to do a bulk transfer test through your exit, to see if it has any spare bandwidth.
Okay, thanks, that'll be on the list.
It might also be worth checking what happens to the bandwidth usage on your Exit over the day and week. A tool like vnstat or munin could help here.
Attached is a graph of network usage from Oct 1 and for 14 days from that, the The peaks/dips are visible. Note that the measures are in Mbps, not MB/s
(Normally, the tor network has daily and weekly peaks.)
Yes, those are quite visible, and would be fairly normal.
Thanks for the help in this, I'm quite a bit miffed that I can't seem to get the bandwidth go up, while the machine appears to not be doing very much.
//D.S
{kind=link}

On Tue, Oct 25, 2016 at 13:26:25 +0200, D.S. Ljungmark wrote:
So far, I'm not sure _why_ it's capping itself on bandwidth, and that's the one thing that I want to figure out before I start scaling out horizontally.
Performance of relays can be a mystery and hard to figure out.
For example, compare the "1 Year graph" for two exits on the same machine, config, network and uptime: https://atlas.torproject.org/#details/01C67E0CA8F97111E652C7564CB3204361FFFA... https://atlas.torproject.org/#details/79861CF8522FC637EF046F7688F5289E49D945... I see no reason for the decline in February on DFRI6 and the low performance after that, compared to DFRI7.
About to upgrade and restart them so the performance will hopefully change thanks to this soon.
tor-relays@lists.torproject.org
-
 Aeris
Aeris -
 D. S. Ljungmark
D. S. Ljungmark -
 D.S. Ljungmark
D.S. Ljungmark -
D.S. Ljungmark
-
Dennis Ljungmark
-
 Johan Nilsson
Johan Nilsson -
 nusenu
nusenu -
 teor
teor -
 Tristan
Tristan -
 Volker Mink
Volker Mink